这个课程不是Codevolution的,而是Ali Alaa这个人的。
Installation
创建项目:pnpm create vite。
安装依赖:
xxxxxxxxxx21pnpm add @tanstack/react-router @tanstack/react-router-devtools2pnpm add -D @tanstack/router-plugin配置Vite插件:
安装tailwind:pnpm add tailwindcss @tailwindcss/vite
配置tailwind:
Code Based Router
TanStack Router 的 code-based router(代码式路由)结构其实非常直白,就是手动用 createRootRoute + createRoute 构建一棵路由树,最后通过 createRouter 创建路由器实例。
官方其实强烈推荐使用 file-based routing(文件系统路由),但如果你就是想用纯代码方式(比如小项目、动态路由特别多、或不喜欢插件生成代码),就可以使用Code based router。
两种方式虽然实现方式不同,但最终形成的routeTree结构是一样的,都要有一个rootRoute。
xxxxxxxxxx91rootRoute2├── indexRoute (/)3├── aboutRoute (/about)4├── postsRoute (/posts)5│ └── postDetailRoute (/posts/$postId)6├── _auth (layout) (不占路径,只是布局)7│ └── dashboard (/_auth/dashboard → /dashboard)8└── login (/login)9 └── etc...二者不同:
| 特性 | code-based | file-based |
|---|---|---|
| 根路径写法 | path: '/' | index.tsx 或 routeTree根 |
| 组织方式 | 手动 .addChildren() | 文件夹 + 插件自动生成 |
| 类型安全强度 | 很好,但需要自己维护 | 极强(插件生成最完整类型) |
| 代码分割 | 需手动 lazy: () => import() | 自动(推荐) |
| 推荐场景 | 非常动态路由、测试、极小项目 | 绝大多数真实项目(官方强烈推荐) |
| 维护成本 | 随着路由增多越来越痛苦 | 几乎恒定 |
参考文档:https://tanstack.com/router/latest/docs/framework/react/routing/code-based-routing
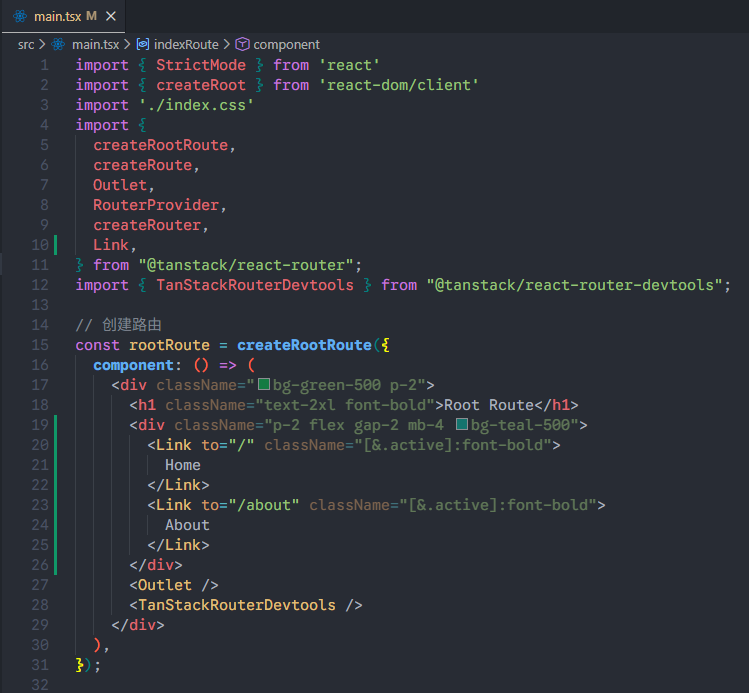
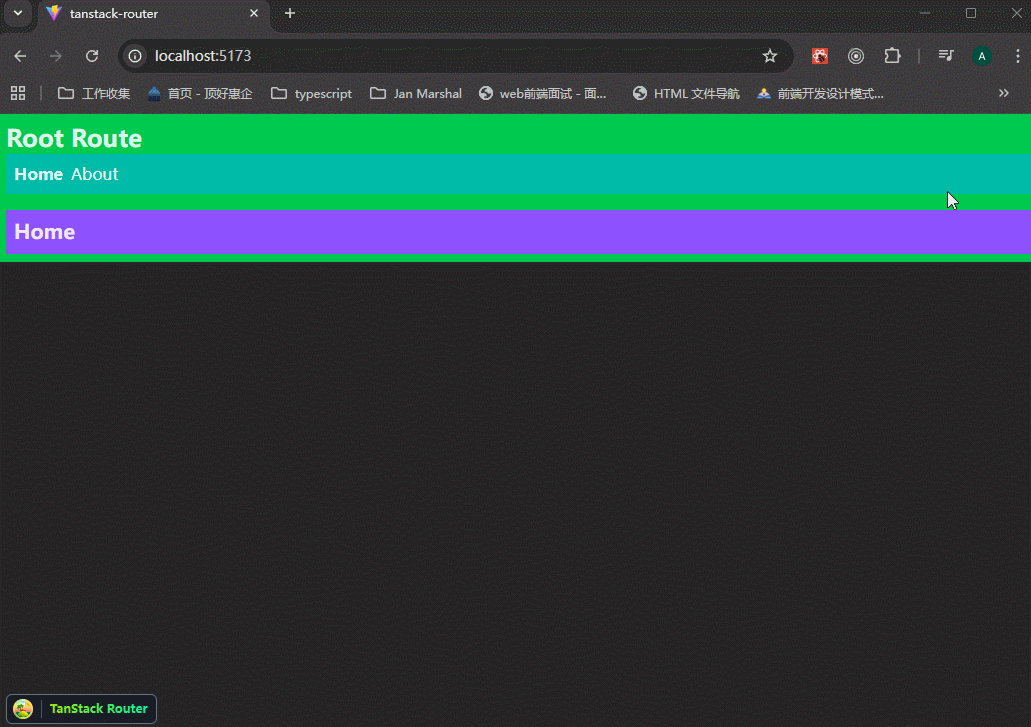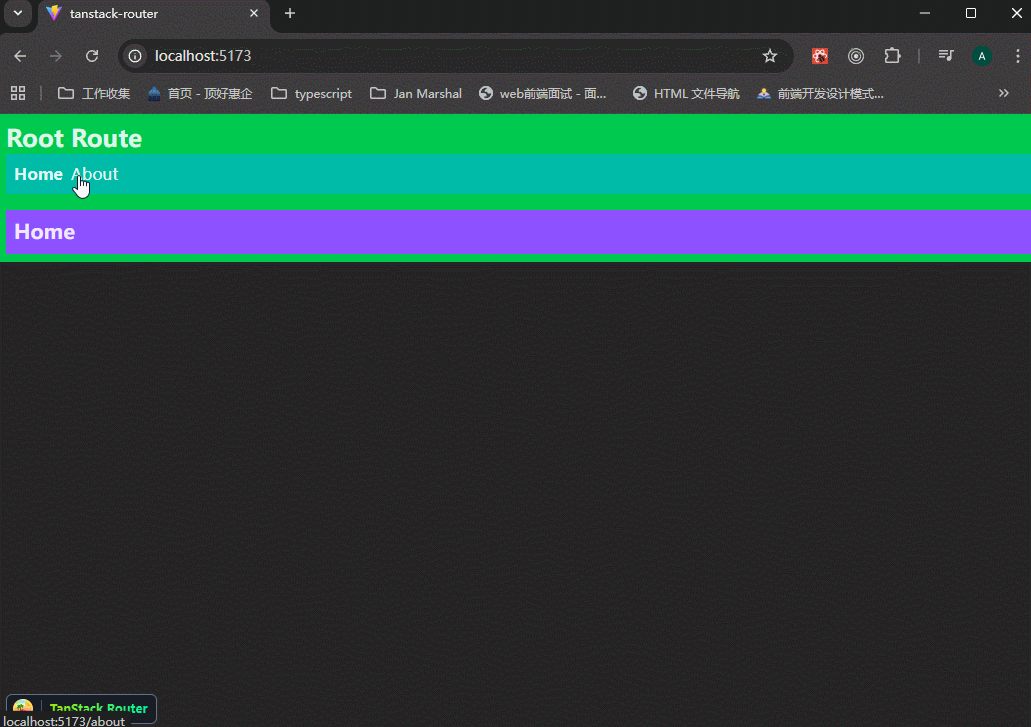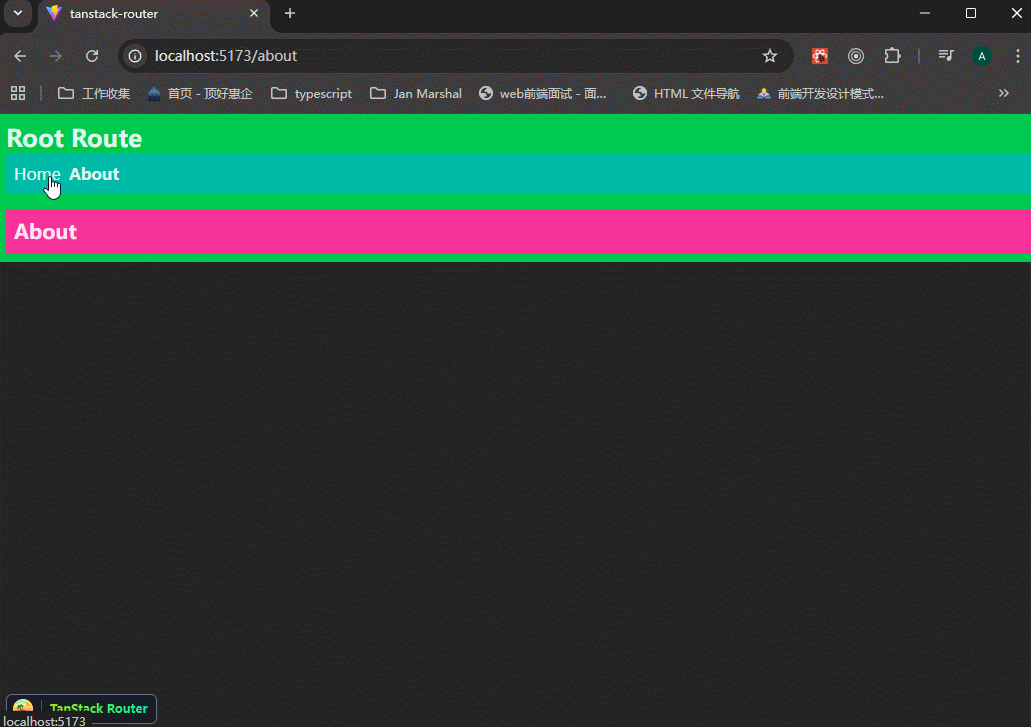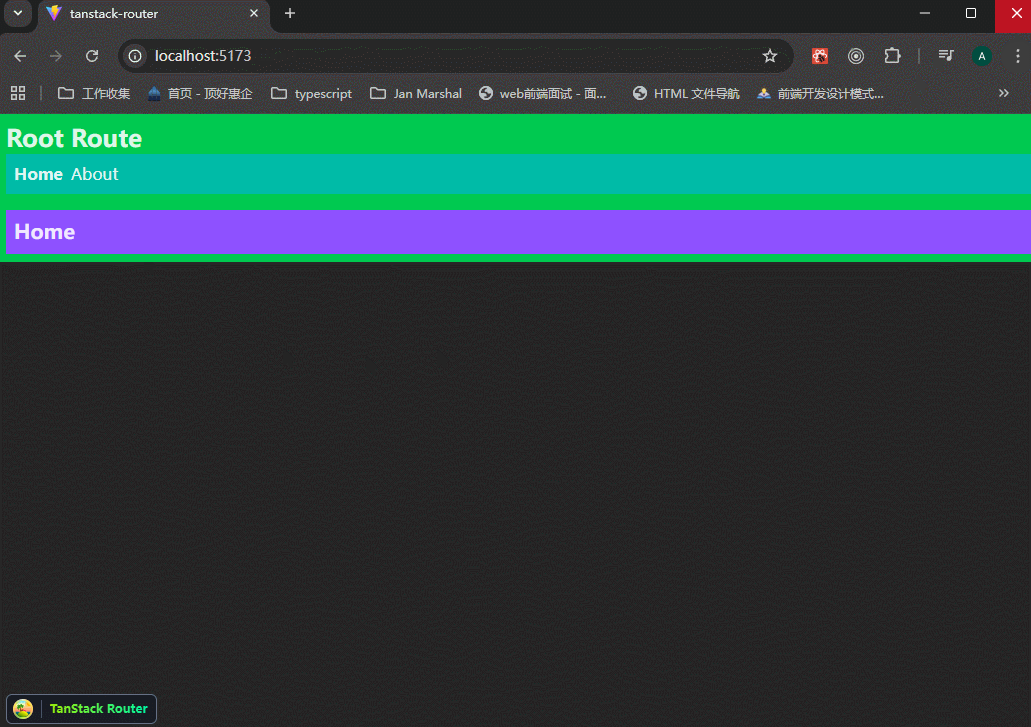
xxxxxxxxxx621// main.tsx23import { StrictMode } from 'react'4import { createRoot } from 'react-dom/client'5import './index.css'6import {7 createRootRoute,8 createRoute,9 Outlet,10 RouterProvider,11 createRouter,12} from "@tanstack/react-router";13import { TanStackRouterDevtools } from "@tanstack/react-router-devtools";1415// 创建路由16const rootRoute = createRootRoute({17 component: () => (18 <div className="bg-green-500 p-2">19 <h1 className="text-2xl font-bold">Root Route</h1>20 <Outlet />21 <TanStackRouterDevtools />22 </div>23 ),24});2526const indexRoute = createRoute({27 getParentRoute: () => rootRoute,28 path: "/",29 component: function Index() {30 return (31 <div className="p-2 bg-violet-500">32 <h3 className="text-xl font-bold">Home</h3>33 </div>34 );35 },36});3738const aboutRoute = createRoute({39 getParentRoute: () => rootRoute,40 path: "/about",41 component: function About() {42 return (43 <div className="p-2 bg-pink-500">44 <h3 className="text-xl font-bold">About</h3>45 </div>46 );47 },48});4950// 手动构建路由树51const routeTree = rootRoute.addChildren([indexRoute, aboutRoute]);5253// Set up a Router instance54const router = createRouter({55 routeTree,56});5758createRoot(document.getElementById("root")!).render(59 <StrictMode>60 <RouterProvider router={router} />61 </StrictMode>62);可以看到,路由跳转正常,使用devtools可以帮助我们跳转路由,并且展示路由树。
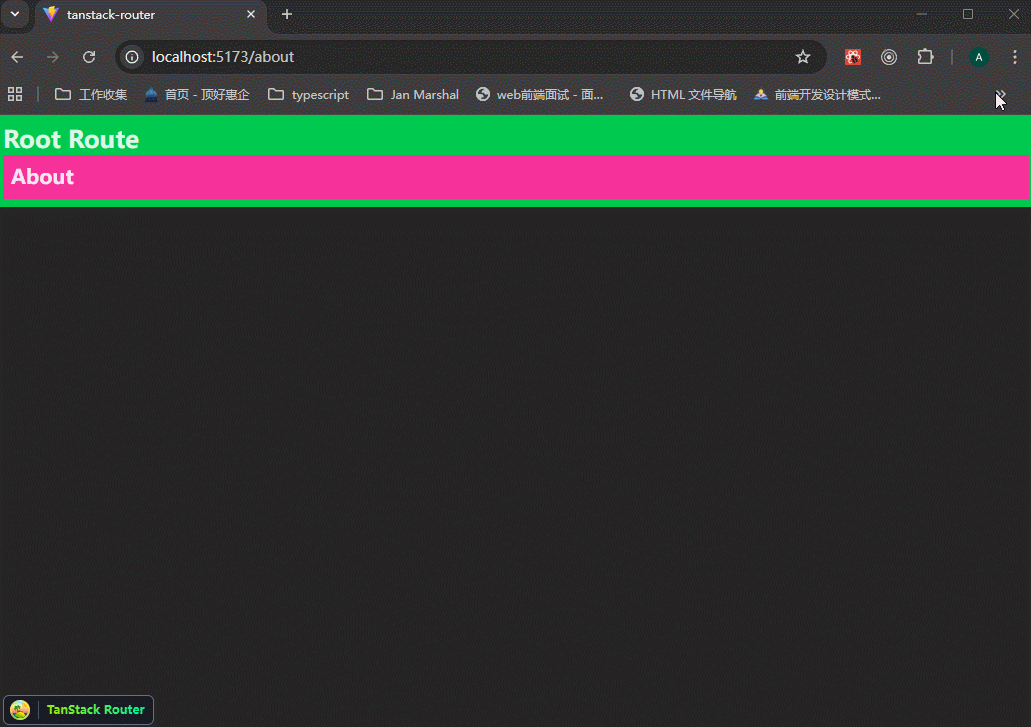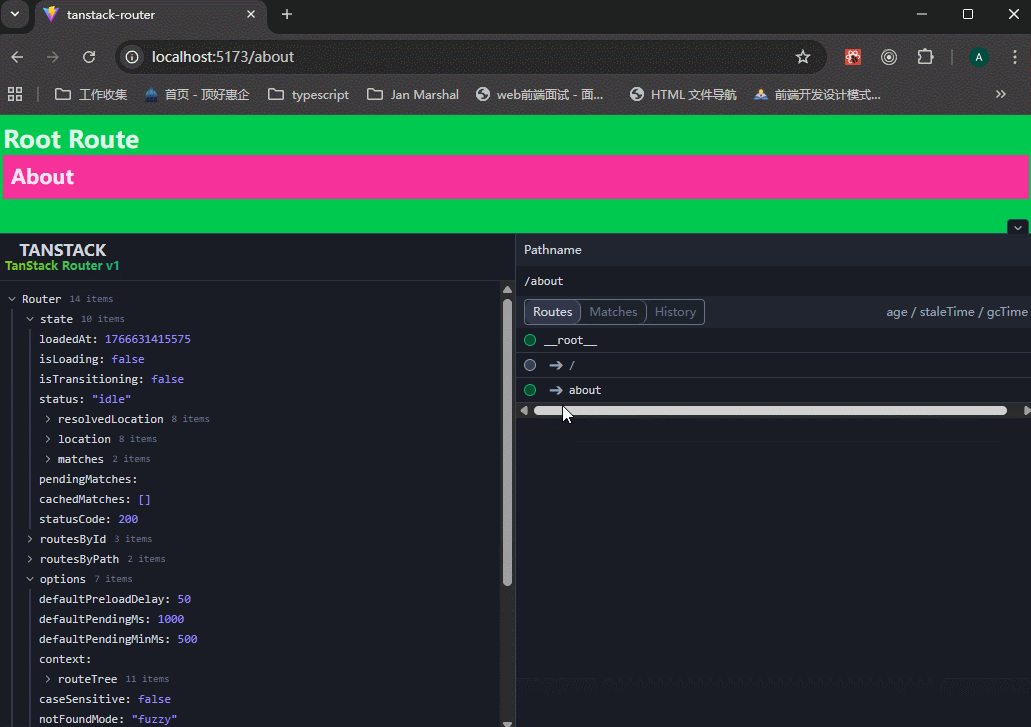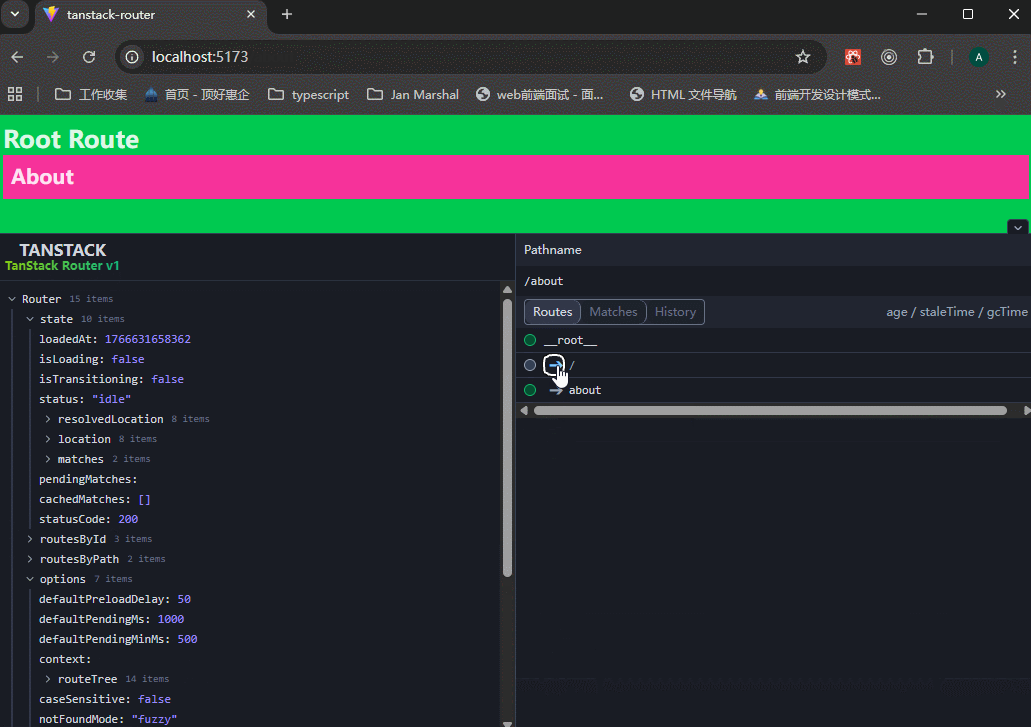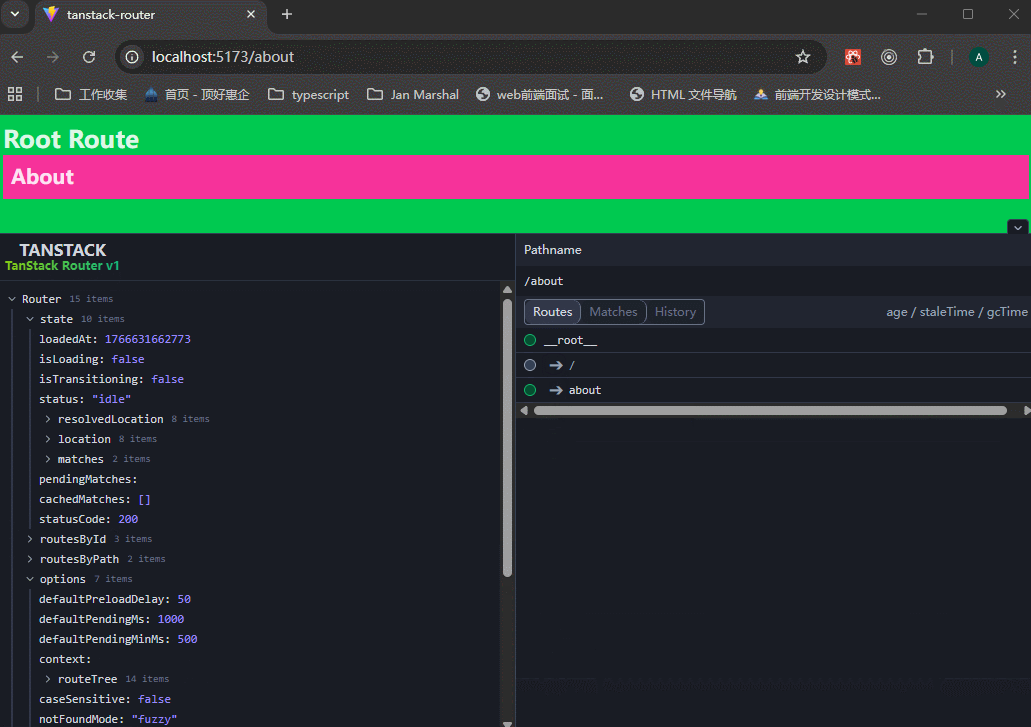
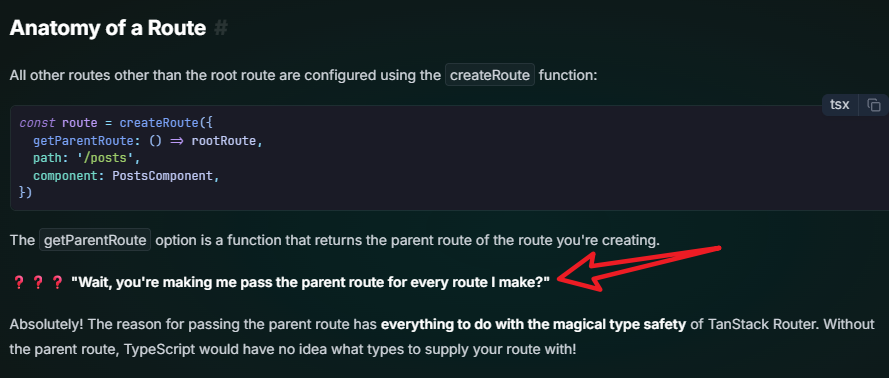
除了rootRoute之外,都使用createRoute方法来创建,必须设置getParentRoute参数。
Navigation Links
使用Link组件来进行路由跳转。
当前路由菜单高亮有多种方法来做,因为当前路由会添加一个active的类名,所以这里直接使用tailwind来做了。
路由跳转正常。
File Based Router
核心工作原理:
你按照特定命名约定写文件 → 构建工具插件(比如说vite插件)(或 CLI)扫描目录 → 自动生成一份类型安全的 routeTree.gen.ts → 你在入口只引入这一行就拥有完整路由树。
我们只需要做第一步:按照约定写文件。
例子:
xxxxxxxxxx171src/2 routes/ ← 约定目录(可改名)3 ├── __root.tsx # 根路由(通常放全局 layout)4 ├── index.tsx # → 对应路径: /5 ├── about.tsx # → /about6 ├── dashboard/7 │ ├── index.tsx # → /dashboard8 │ ├── route.tsx # 显式路由文件(可选)9 │ ├── _layout.tsx # → 布局路由(渲染 <Outlet />)10 │ ├── users/11 │ │ └── $userId.tsx # → /dashboard/users/:userId12 │ └── settings/13 │ ├── index.tsx # → /dashboard/settings14 │ └── .tsx # 故意忽略(文件名前面加 . 或 _ 开头通常忽略)15 └── posts/16 ├── $slug.tsx # → /posts/:slug17 └── $ # 贪婪匹配(splat) → /posts/后面全部常用的几种特殊文件名约定:
| 文件名写法 | 对应路径 | 说明 | 常用场景 |
|---|---|---|---|
| index.tsx | 当前层级根路径 | 经典约定 | 列表页、首页 |
| route.tsx | 当前层级根路径 | 显式写 route 时优先(更清晰) | 想放很多同文件时 |
| $param.tsx | /:param | 动态参数 | 用户详情、文章页 |
| $ | /* | 贪婪匹配(splat) | 404、catch-all |
| _layout.tsx | 布局路由 | 只渲染自己 + children 的 | 侧边栏、顶部导航 |
| dashboard.tsx | /dashboard(不嵌套) | 下划线 _ 打断父级嵌套关系 | 特殊页面跳出布局 |
| users._index.tsx | /users (不嵌套) | 父目录加 _ 断开嵌套 | 独立页面 |
| posts._$slug.tsx | /posts/:slug (不嵌套) | 组合用法 | — |
基本使用
在src下插件routes文件夹,然后创建文件,@tanstack/router的vite插件,会帮助我们自动生成范例代码,我们只需要进行相应修改即可,太方便了:
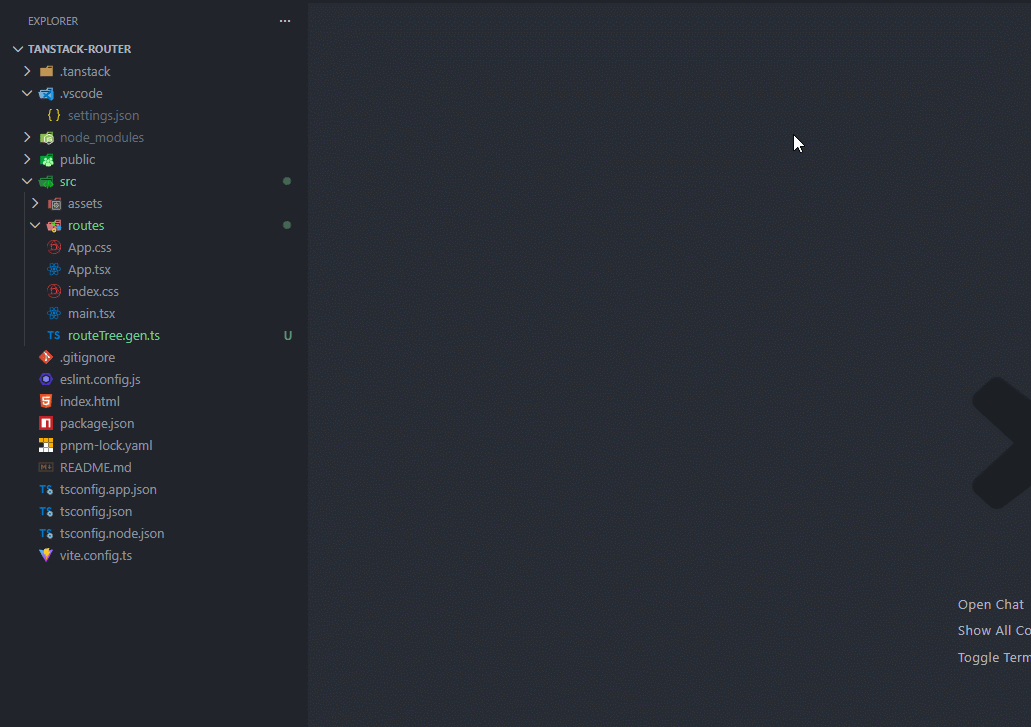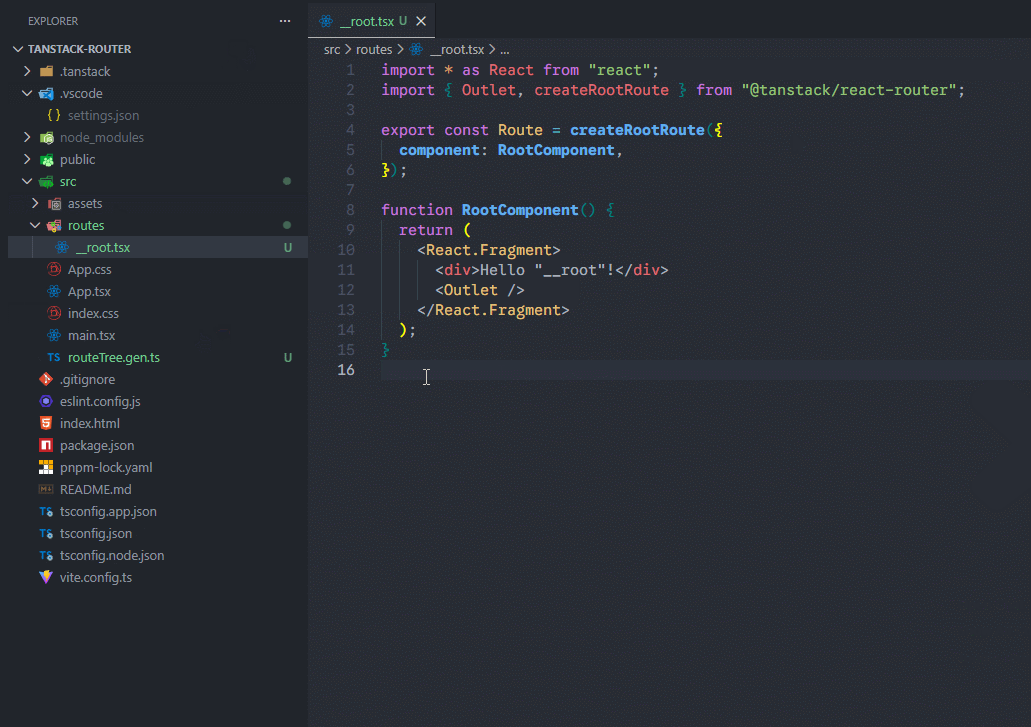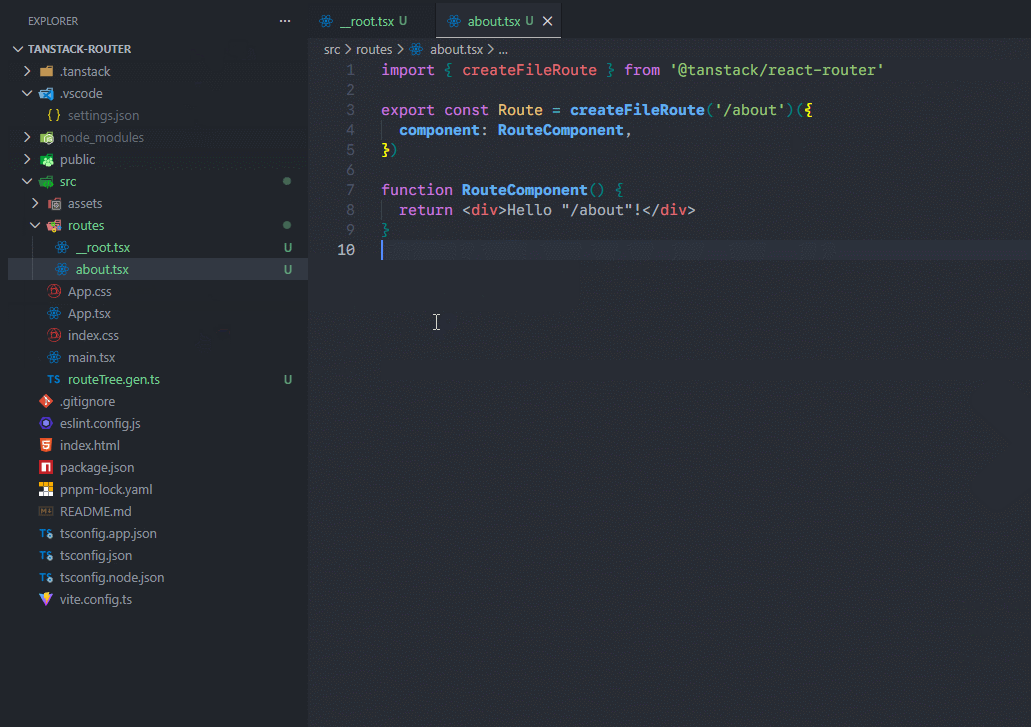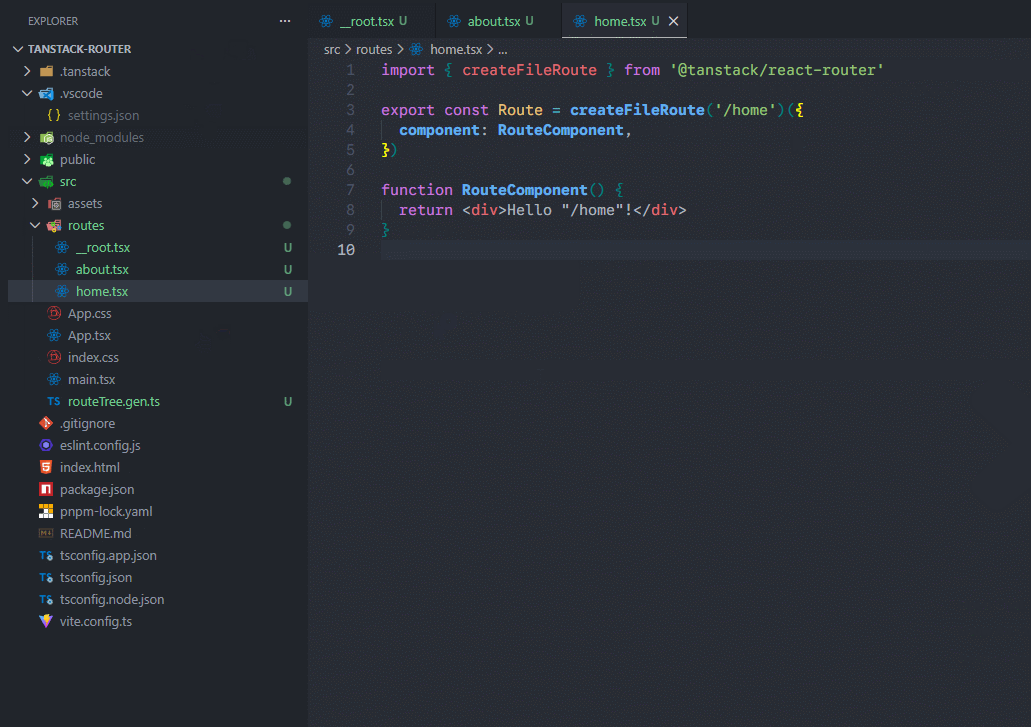
下一步就简单了,将之前定义好的组件内容粘贴过来即可,我粘贴root过来示范:
xxxxxxxxxx291// src/routes/__root.tsx23import * as React from "react";4import { Link, Outlet, createRootRoute } from "@tanstack/react-router";5import { TanStackRouterDevtools } from "@tanstack/react-router-devtools";67export const Route = createRootRoute({8 component: RootComponent,9});1011function RootComponent() {12 return (13 <React.Fragment>14 <div className="bg-green-500 p-2">15 <h1 className="text-2xl font-bold">Root Route</h1>16 <div className="p-2 flex gap-2 mb-4 bg-teal-500">17 <Link to="/" className="[&.active]:font-bold">18 Home19 </Link>20 <Link to="/about" className="[&.active]:font-bold">21 About22 </Link>23 </div>24 <Outlet />25 <TanStackRouterDevtools />26 </div>27 </React.Fragment>28 );29}在ruotes里面创建了文件之后,在src文件夹中会自动生成routeTree.gen.ts文件,这是插件帮助我们自动生成的,里面有一个routeTree暴露出来。
然后在main.tsx里面引入routeTree来使用。
可以看到,路由正常。
Nesting Routes
只要文件放在某个目录下,默认就会成为该目录对应路由的子路由。这是tanstack/router的基本约定。
这节课讨论两种情况。
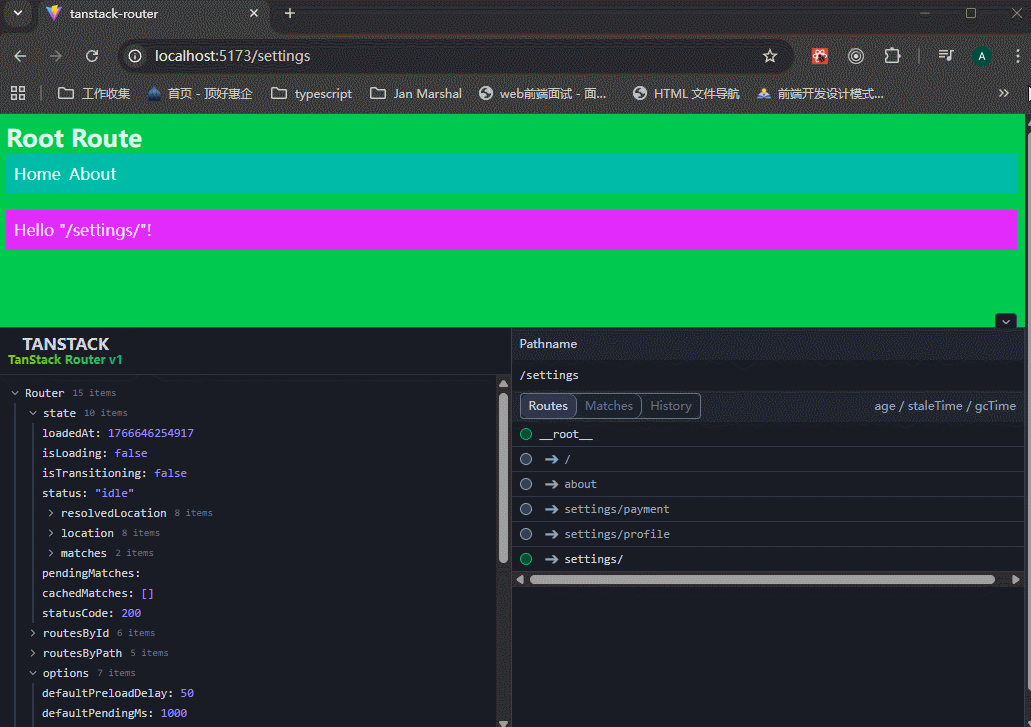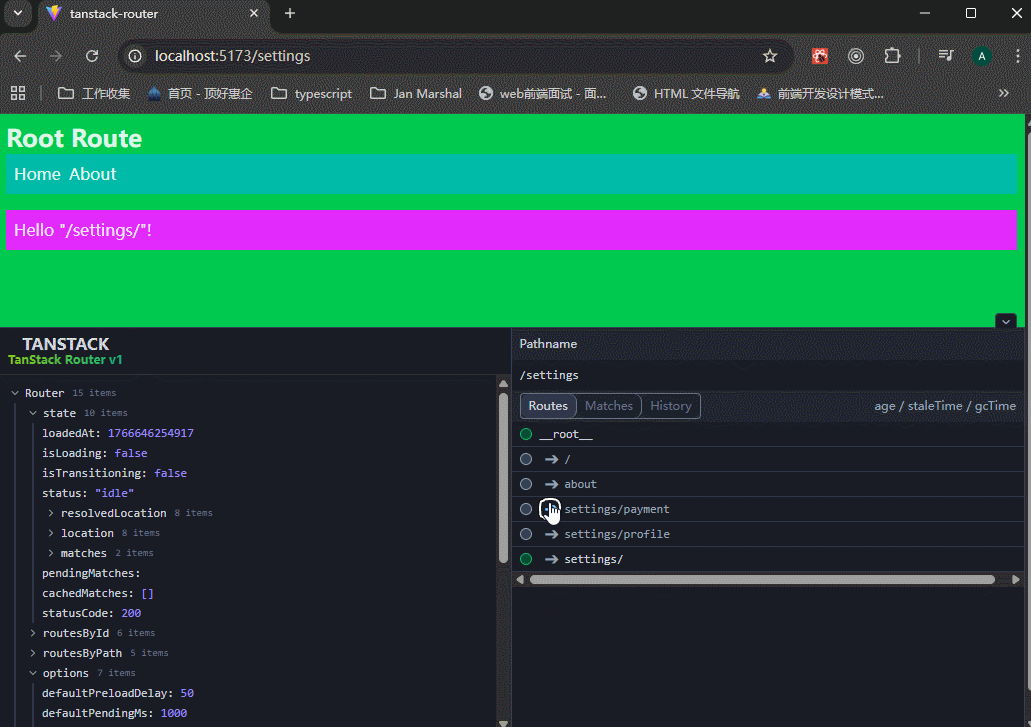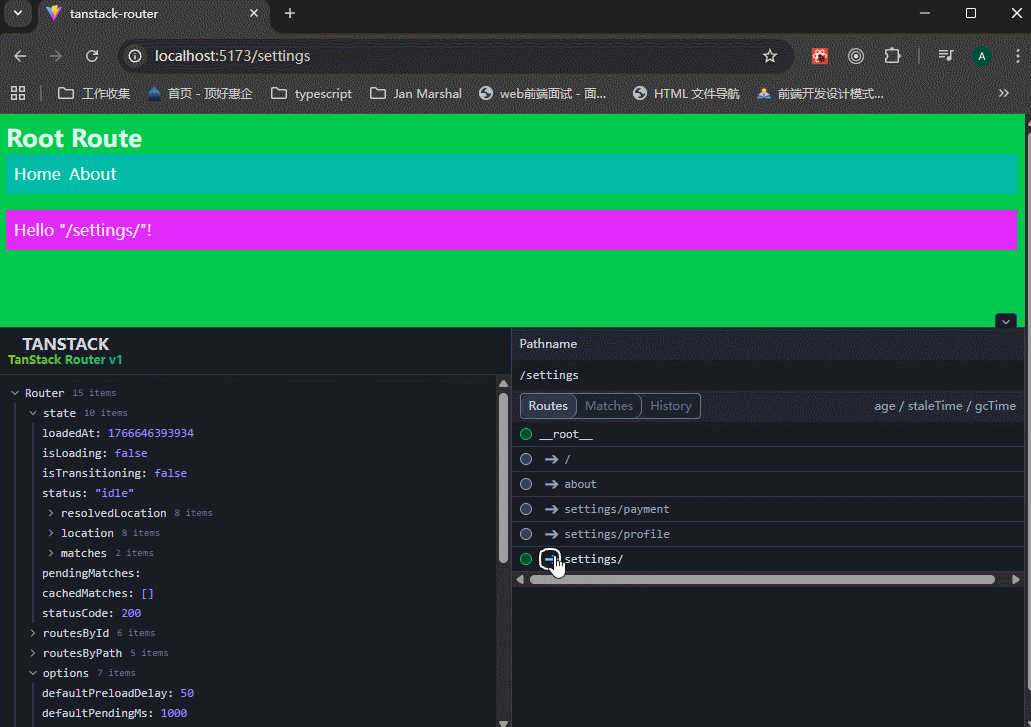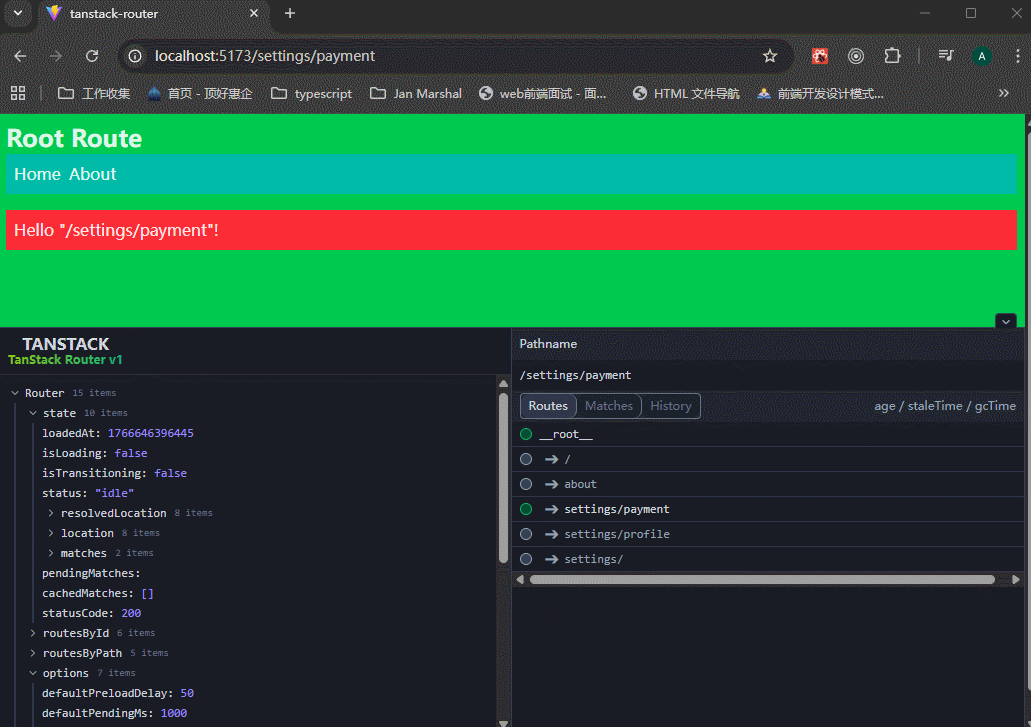
1、index.tsx和route.tsx的区别

index.tsx
当一个文件夹里面是index.tsx文件时,表示该目录的「默认/索引」页面,目录路径精确匹配时才会显示这个页面。
可以看到,生成的routeTree里面,有三个路由地址。
route.tsx
表示该目录的「主路由定义文件」(通常用来做 layout),非常适合做父级,能自然包含所有子路由。
要结合<Outlet />一起使用。
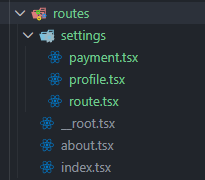
可以看到,生成的routeTree里面,有两个路由地址。
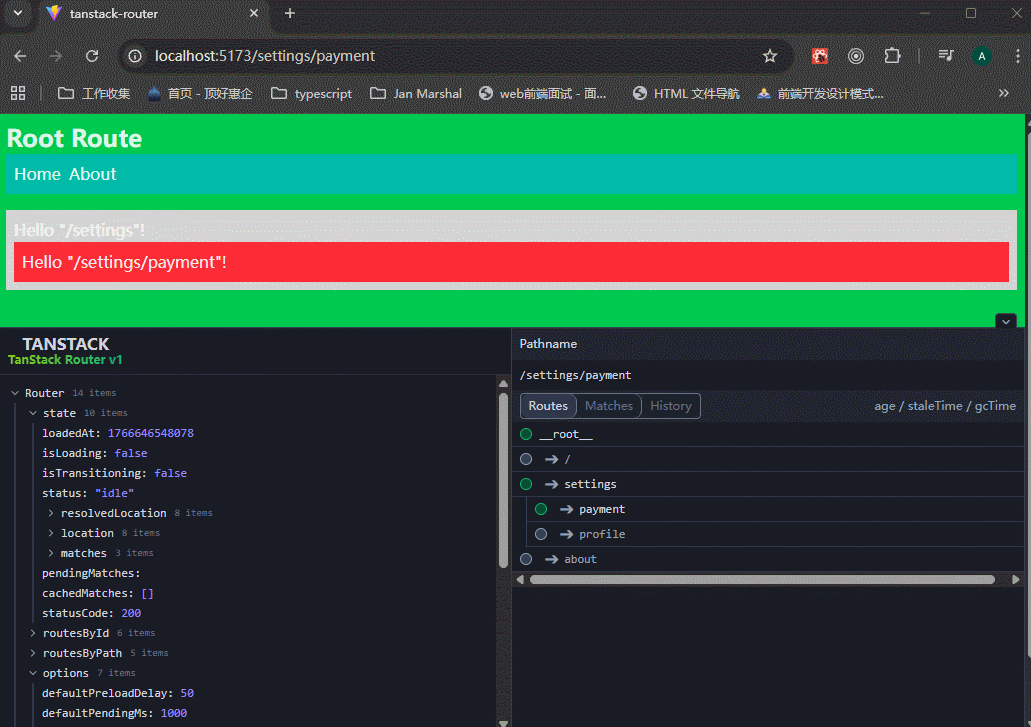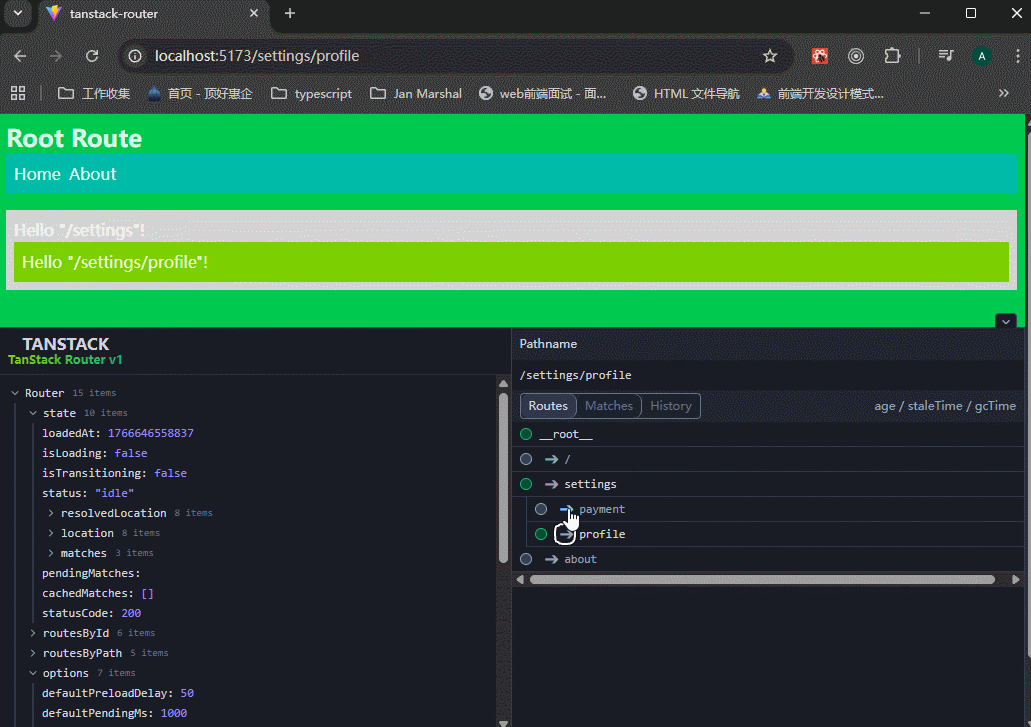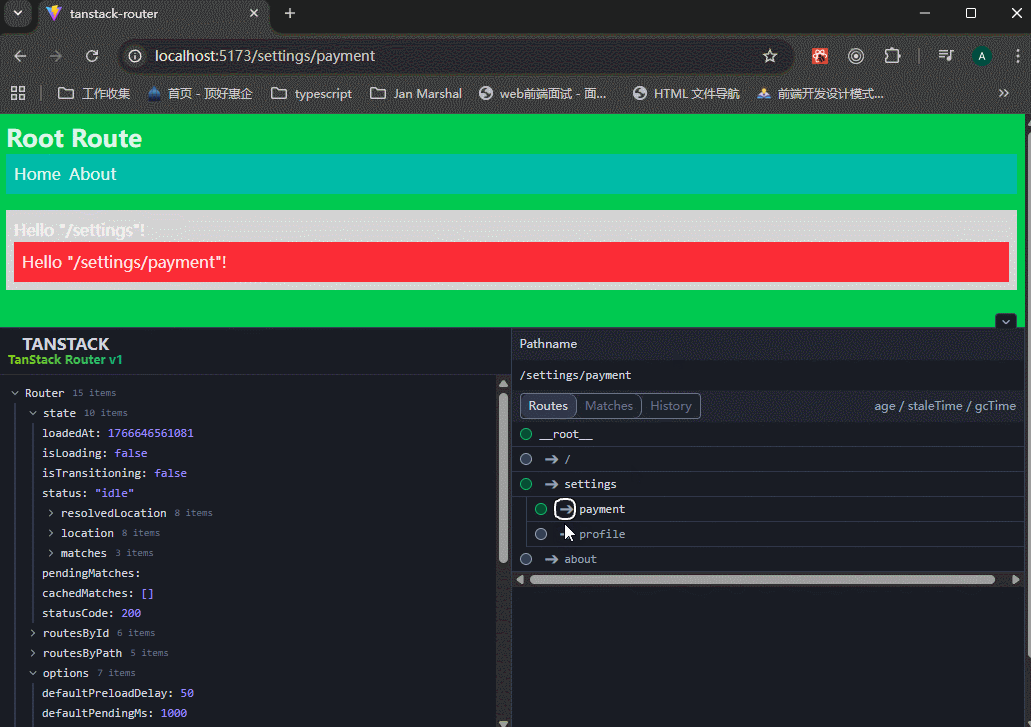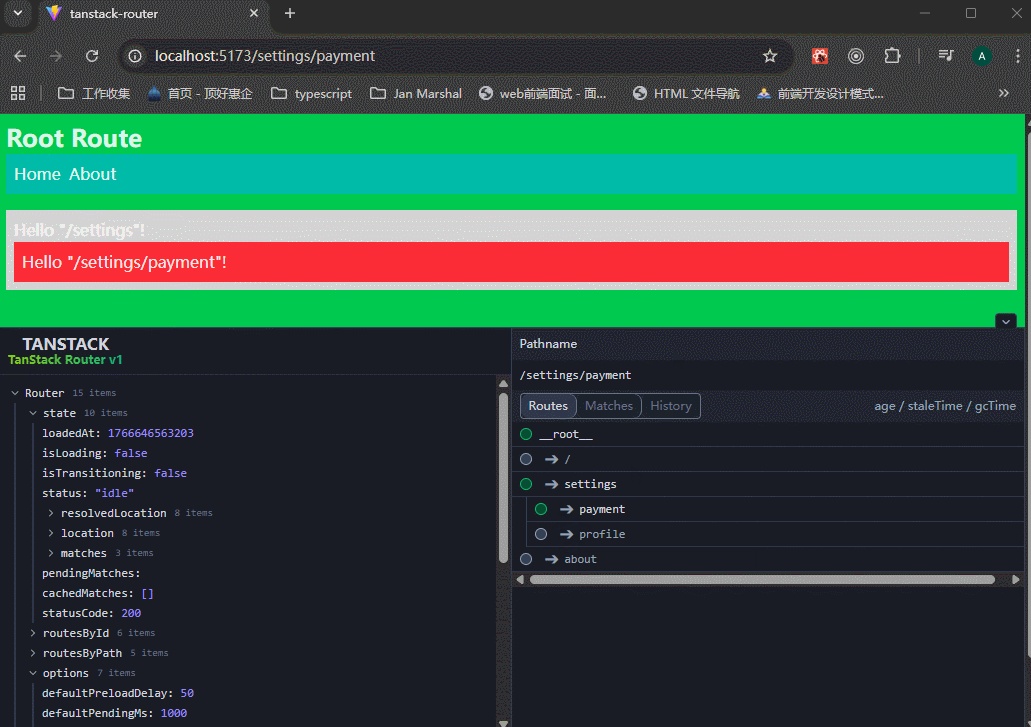
xxxxxxxxxx51# 两种等价的布局写法(社区两种最常见风格)2dashboard/3├── route.tsx # 风格1:简洁、直观4# 或5├── _layout.tsx # 风格2:更明确是布局(类似 Next.js 早期)
快速决策表(开发中最常用的选择指南)
| 你的需求 | 推荐写法 | 为什么? |
|---|---|---|
| 这个目录只需要一个页面 | 只放 index.tsx | 最简单、最直观 |
| 这个目录需要布局(侧边栏、顶部导航等) | route.tsx + | 布局逻辑清晰,所有子页面自动共享 |
| 想要布局 + 自己的默认内容页 | route.tsx(布局) + index.tsx(内容) | 不推荐这样写,会造成冲突,推荐使用_layout.tsx + index.tsx |
| 目录里已经有 route.tsx,还想加默认页 | 加 index.tsx | 正常工作(只要不冲突) |
| 同时放了 index.tsx 和 route.tsx 报错了 | 删除其中一个,或改用 _layout.tsx | 路由生成器不允许同一个路径有两种定义文件 |
2、文件名或目录名后面加_
Route segments with the _ suffix exclude the route from being nested under any parent routes.
表示断开嵌套关系。注意:不是路由地址断开嵌套,而是页面内容断开嵌套。
文件名或目录名后面的下划线是一个“解耦”工具。它允许你保持 /parent/child 这样的优雅 URL 结构,同时又能在 UI 层面灵活地摆脱父级组件(Layout)的束缚。
| 路由文件 | URL 路径 | 是否渲染在 dashboard 布局内 |
|---|---|---|
dashboard/index.tsx | /dashboard | 是 |
dashboard/profile.tsx | /dashboard/profile | 是 |
dashboard_/billing.tsx | /dashboard/billing | 否(独立全屏渲染) |
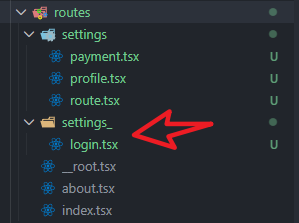
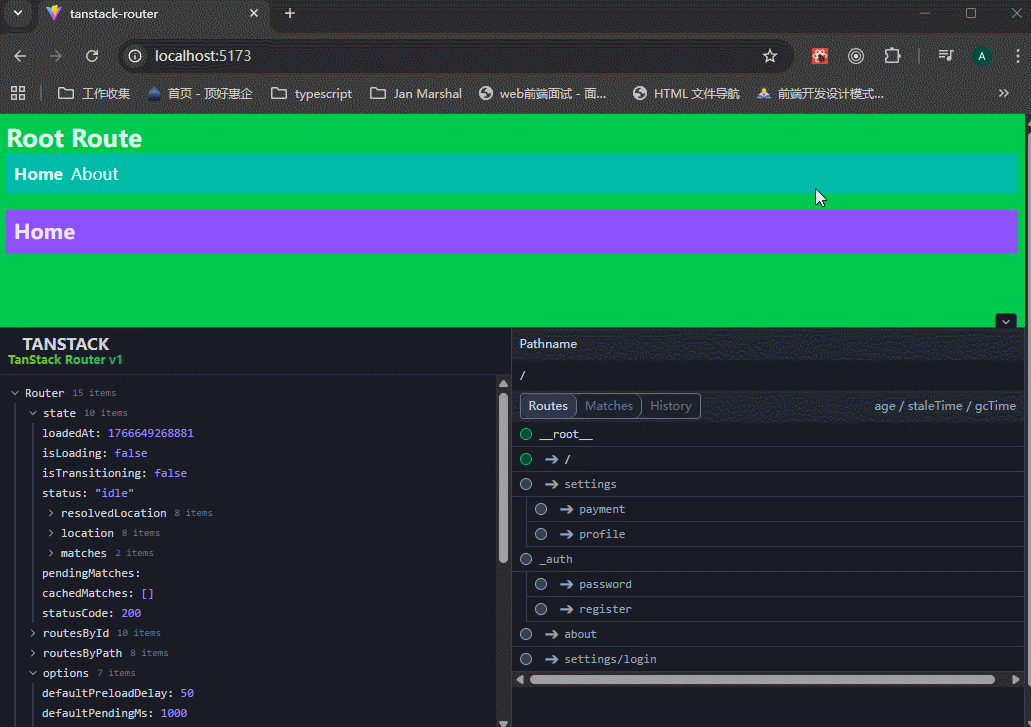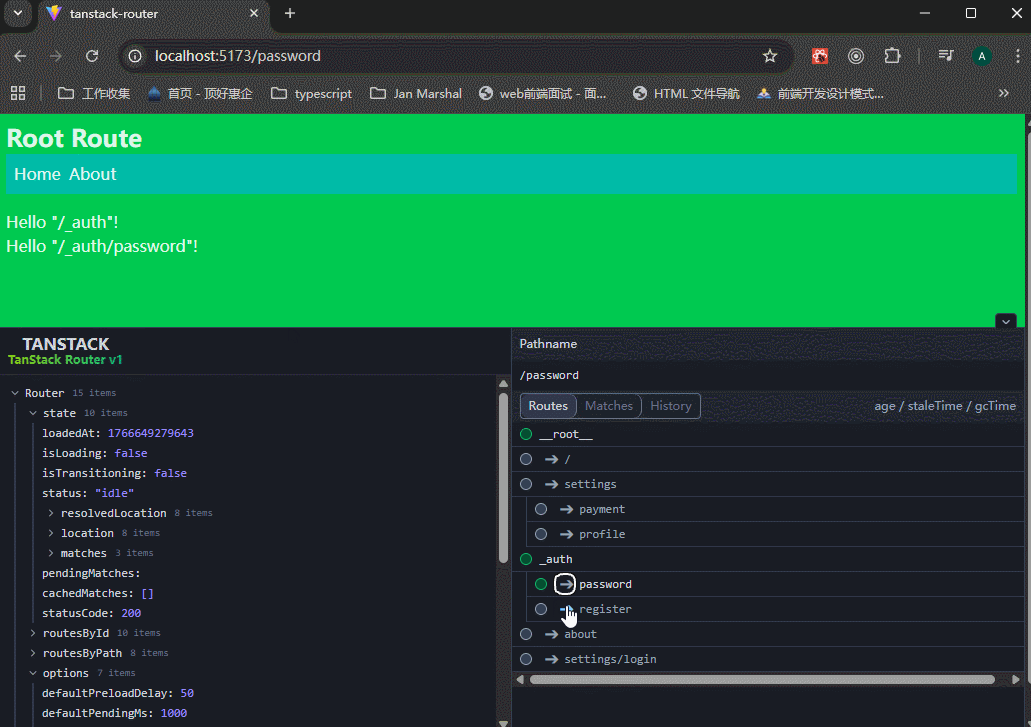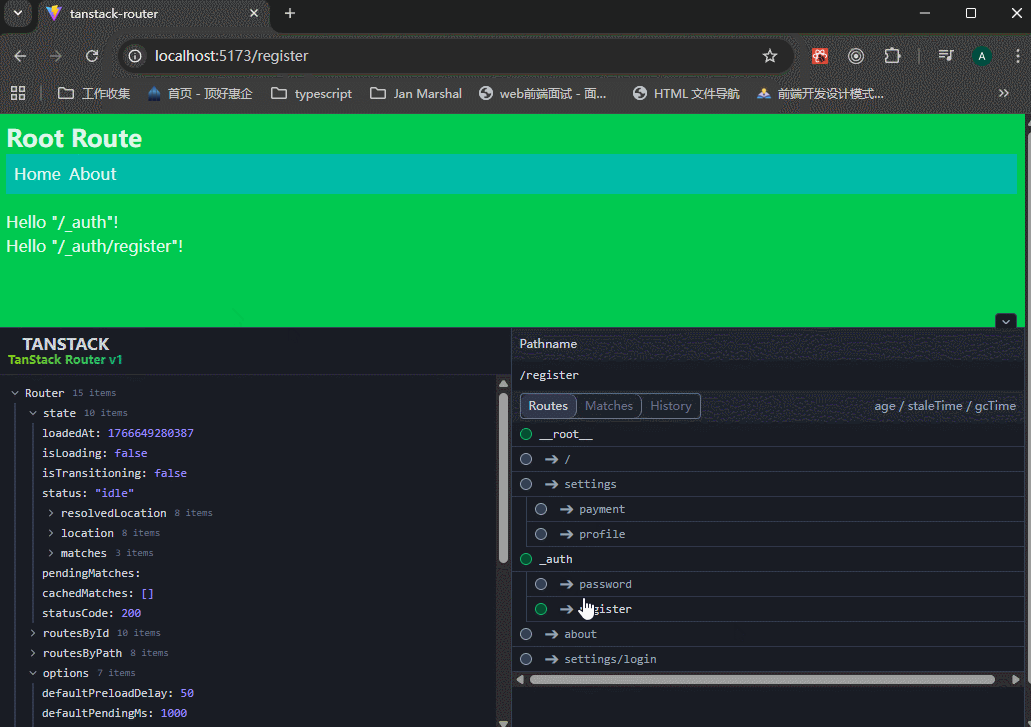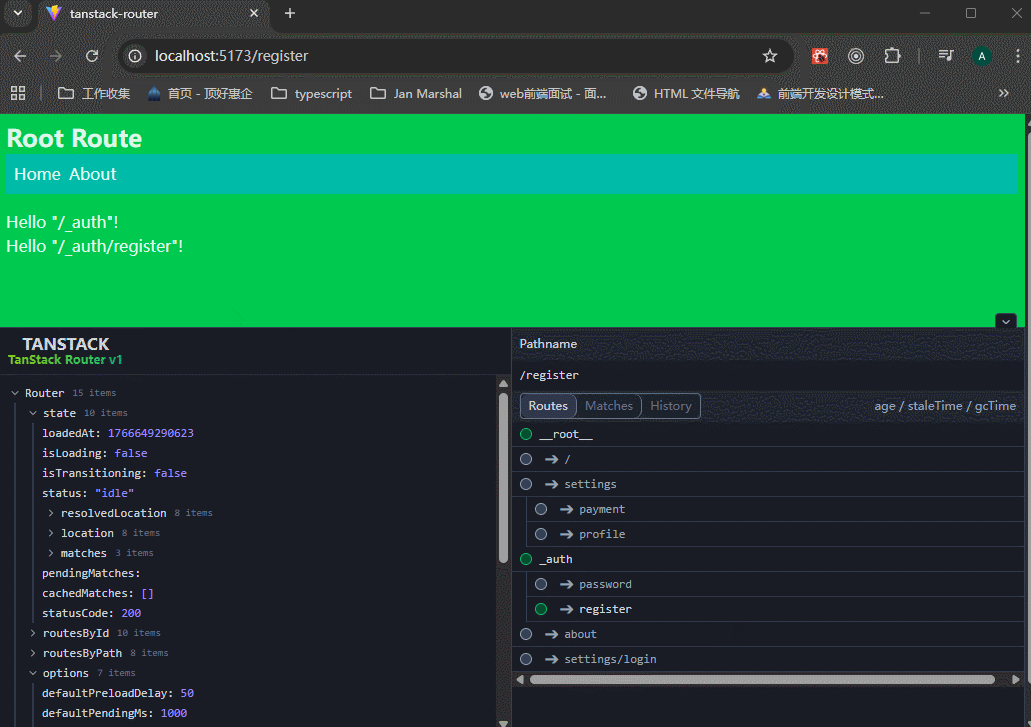
注意看,路由地址在settings之间改变,但是settings/login页面的内容就不会被settings文件夹里面的任何内容影响。
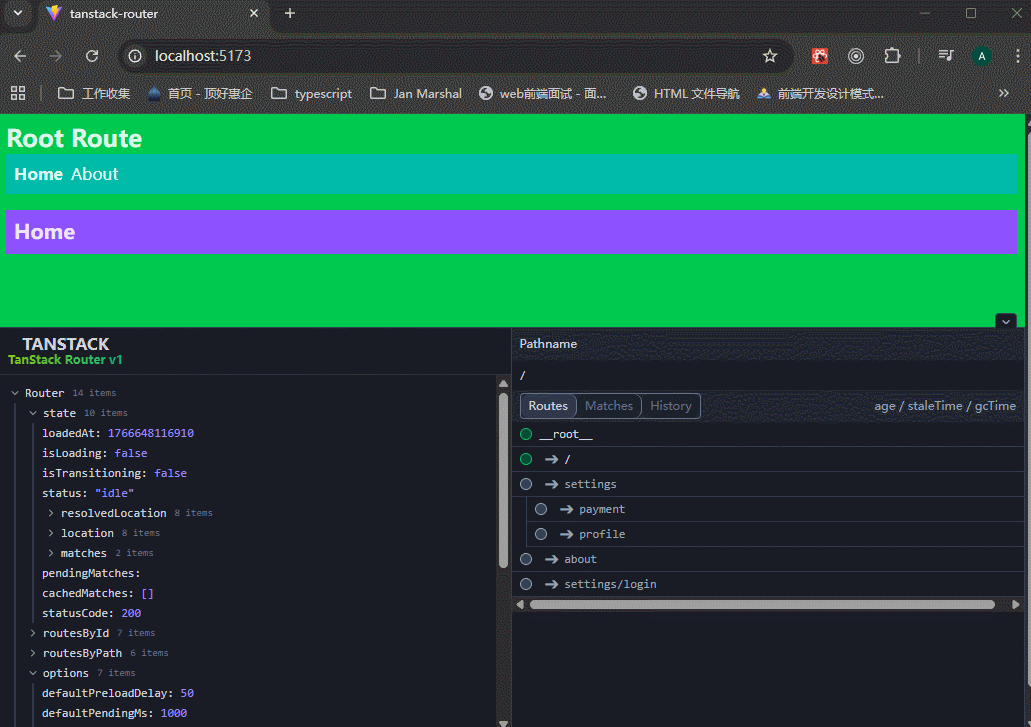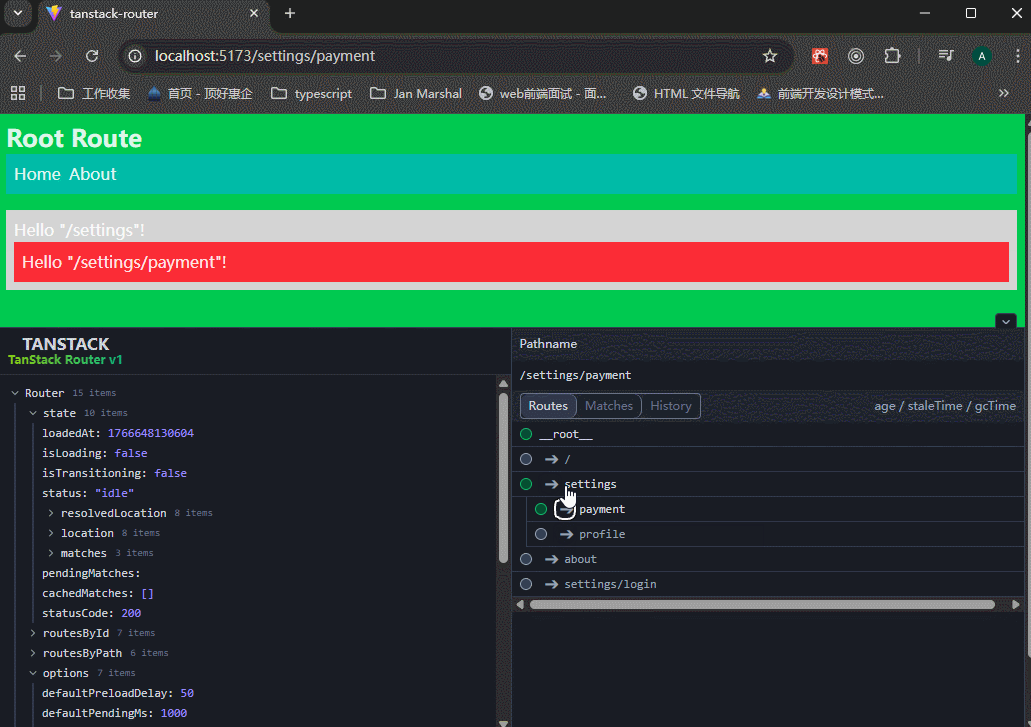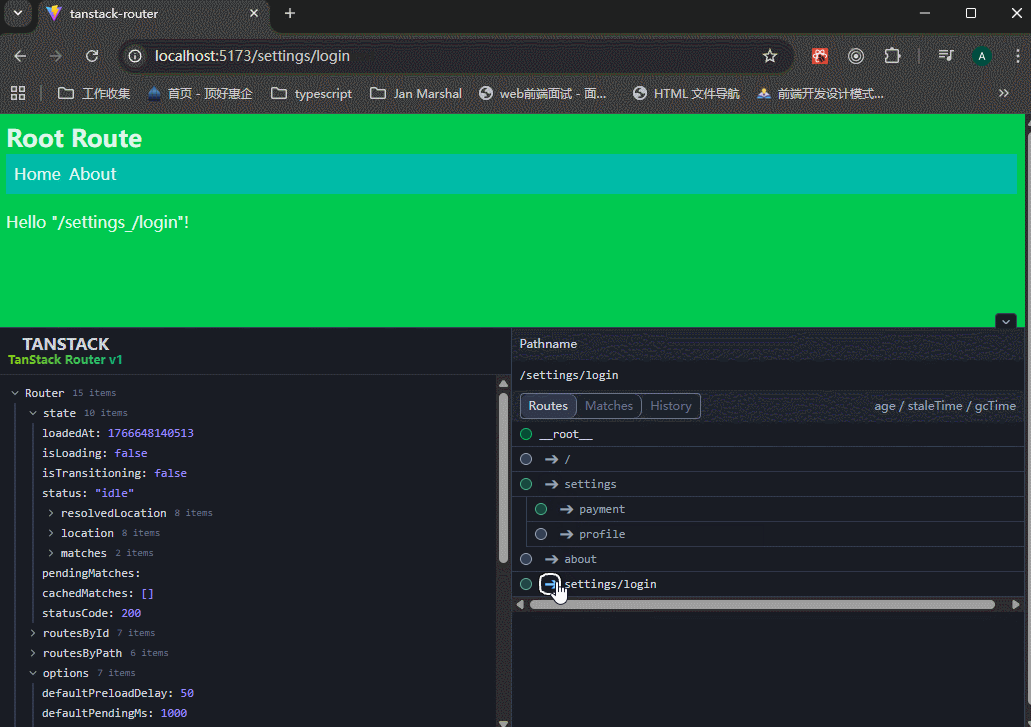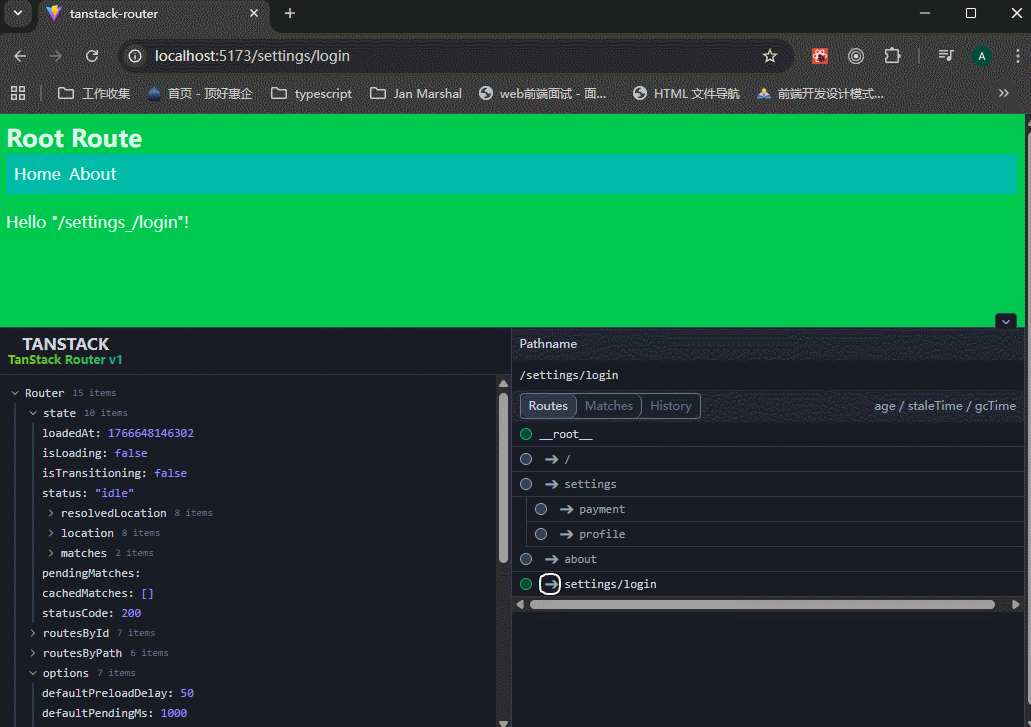
xxxxxxxxxx61想让子页面有父布局? → 在父目录放 _layout.tsx(最推荐)2父路由自己也有内容? → 放 index.tsx 或者 route.tsx3不想被父布局包? → 文件名/目录名前面加 _ (下划线断开)4想要分组但不要路径前缀? → 用括号 (group) 做分组目录5想要动态参数? → $param.tsx6想要全部剩余路径? → $xxx.tsx 或者单纯一个 $ 文件解决 TanStack Router 所有“隐式 any”问题的终极方案。你需要确保在项目的入口文件(如
main.tsx或App.tsx)中添加了类型声明。加了这段声明之后,可以省很多心。xxxxxxxxxx91// 在创建 router 实例的地方2const router = createRouter({ routeTree })34// 必须添加这段声明,TS 才能全局感知每个路由的 Search Params 类型5declare module '@tanstack/react-router' {6interface Register {7router: typeof router8}9}
Pathless Layouts
在 TanStack Router 中,前缀下划线(例如 _layout.tsx 或 _auth/)被称为 Pathless Route(无路径路由)。
它的核心作用是:为了逻辑分组或 UI 嵌套,但不在 URL 路径中显示。
1. 核心定义
当你给文件夹或文件加上 _ 前缀时,你是在告诉路由器:
- UI 层面:我想通过这个文件创建一个布局(Layout)或共享一个逻辑(如权限检查)。
- URL 层面:请忽略这个名字,不要把它加到浏览器的地址栏里。
2. 实际案例对比
假设你的需求是:/login 和 /register 页面需要共享一个蓝色的背景和公司的 Logo。
❌ 不使用前缀的情况
如果你的结构是:
auth/login.tsxregister.tsx
生成的 URL:/auth/login 和 /auth/register。
✅ 使用前缀 _ 的情况
如果你的结构是:
_auth.tsx(布局组件,包含蓝色背景和 Logo,需要加<Outlet />)_auth/login.tsxregister.tsx
生成的 URL:/login 和 /register。 虽然 URL 里没有 auth,但这两个页面都会自动嵌套在 _auth.tsx 的 <Outlet /> 中。
3. 三大使用场景
① 视觉布局分组 (Visual Grouping)
这是最常见的用法。你可能希望“营销页”用一套导航栏,“管理后台”用另一套导航栏,但 URL 都想从根目录开始(如 /home 和 /dashboard)。
_marketing/home.tsx->/home_admin/dashboard.tsx->/dashboard
② 逻辑与权限控制 (Auth/Logic Wrappers)
你可以创建一个 _authenticated.tsx 文件,在里面编写重定向逻辑:如果用户未登录,则跳转到登录页。所有放在 _authenticated/ 文件夹下的路由都会自动受到这个逻辑的保护,而 URL 中不会多出 /authenticated/ 这一层。
③ 纯粹的文件组织
当你的项目非常大时,你可能只想把相关的页面放在一起管理,但不希望改变现有的 SEO 友好的 URL 结构。
注意看,路由地址是很简洁的,同时也有_auth.tsx文件的内容。
pathless route不只是可以省略一段url path,更重要的是共享一段逻辑或样式。
如果单纯的只是想要省略一段url path,那么可以使用
(folder),小括号来实现。
Ignored Folders
- Prefix
有时候,我们想就近编写一些组件,而不是都放到src/components这个文件夹里面。但是一个文件夹就是一个路由地址,该怎么办才能让tanstack/router忽略这个文件夹呢?
可以在文件夹或者文件名前面加上-,这样就会排除出路由树了。
Files and folders with the - prefix are excluded from the route tree. They will not be added to the routeTree.gen.ts file and can be used to colocate logic in route folders.
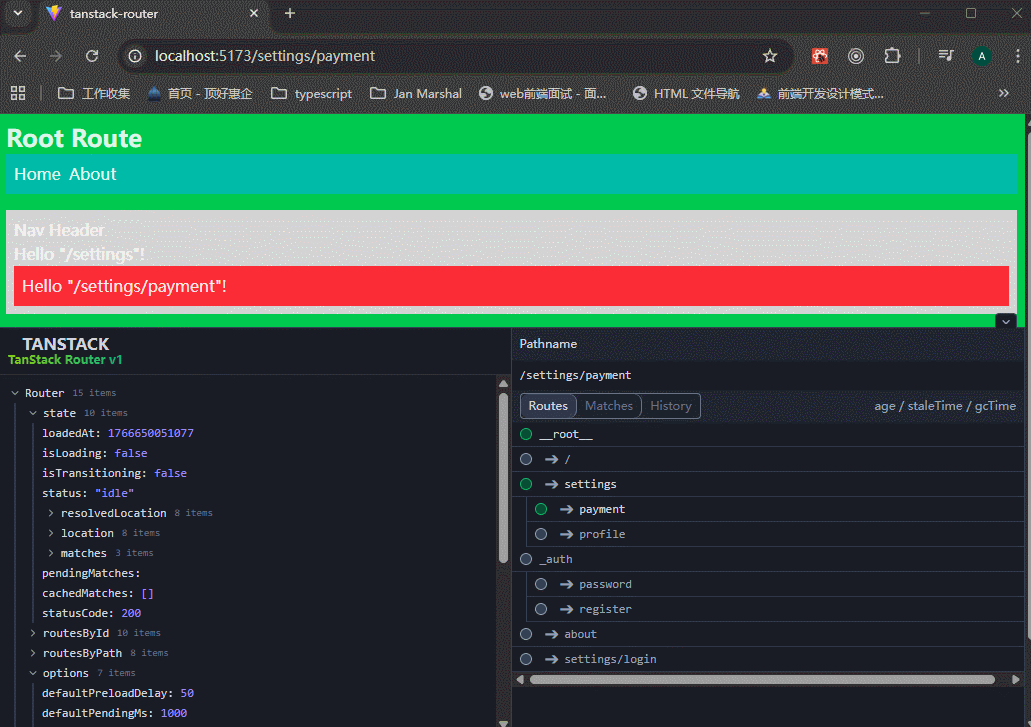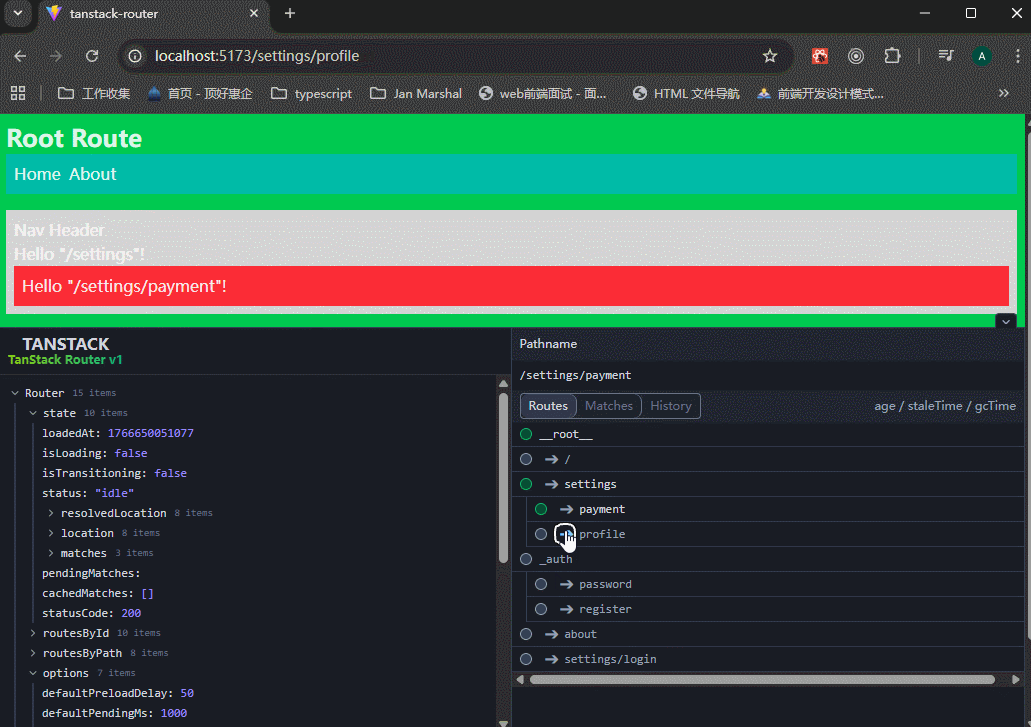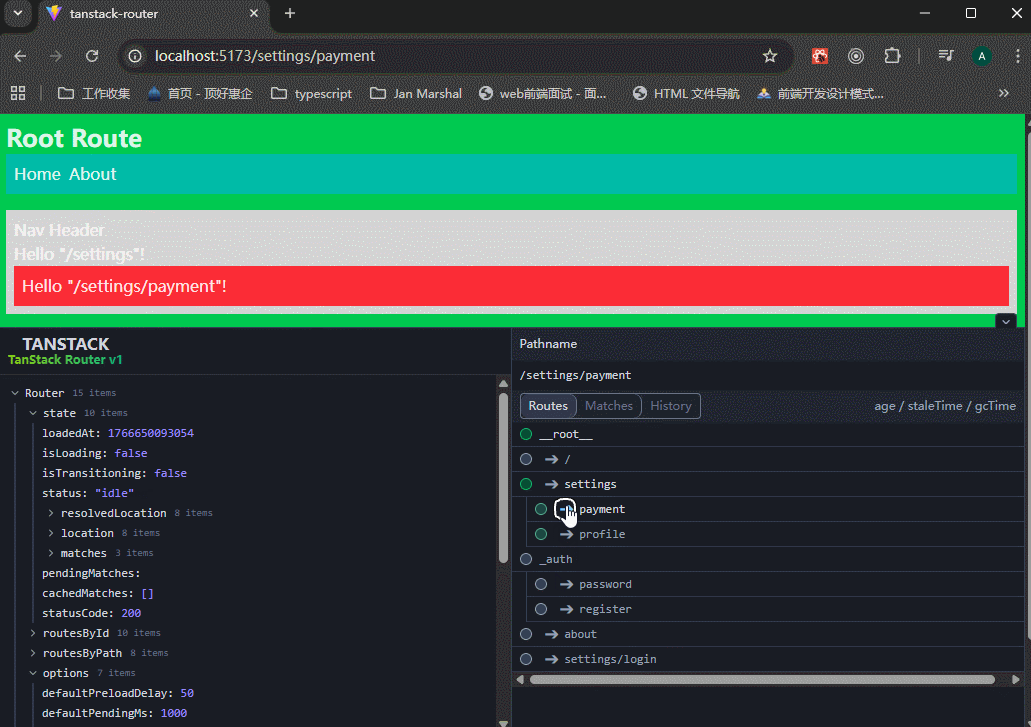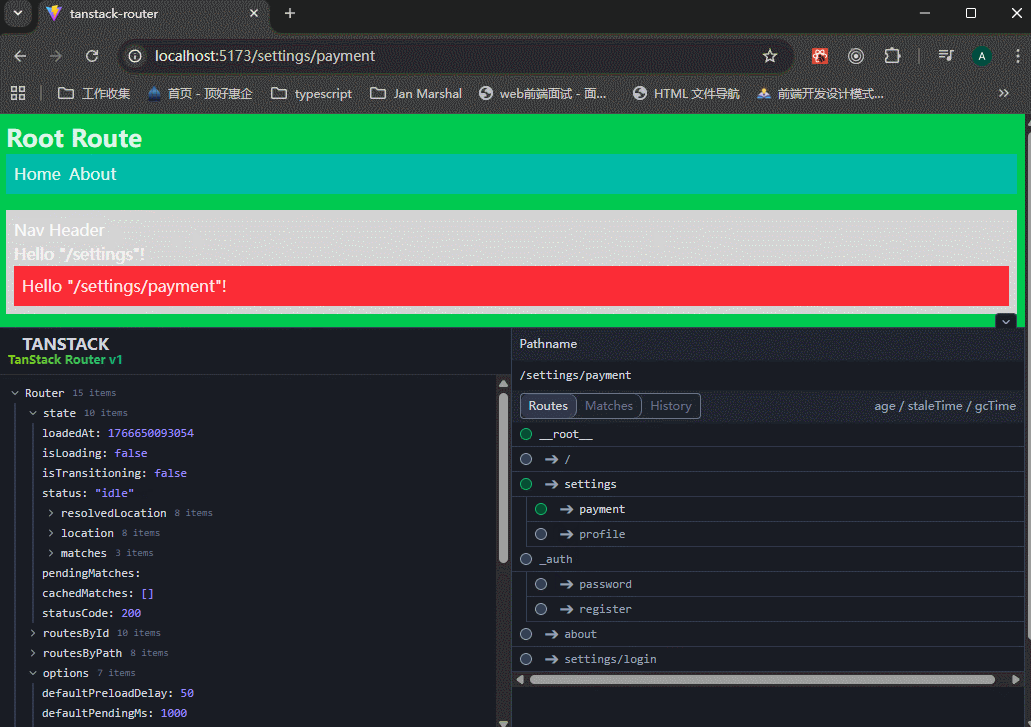
可以看到,Nav组件正常使用了。
(folder) folder name pattern
A folder that matches this pattern is treated as a route group, preventing the folder from being included in the route's URL path.
路由分组。它纯粹是为了组织文件,完全不影响路由的层级。
核心作用
- 不影响 URL 路径:括号里的名字不会出现在地址栏。
- 不增加 UI 布局层级:这是它与
_layout(前缀下划线)最大的不同。它不会寻找一个所谓的“布局文件”来嵌套子页面,它只是一个逻辑上的文件夹。
| 符号 | 位置 | 官方术语 | 作用 |
|---|---|---|---|
_ | 前缀 | Pathless Layout | 隐藏路径,但保留 UI 布局嵌套 |
_ | 后缀 | Non-nested Route | 保留路径,但跳出父级 UI 布局 |
() | 包裹 | Route Group | 隐藏路径,且不产生 UI 布局嵌套 |
. | 中间 | Flat Route | 扁平化文件命名,代替多层文件夹 |
Flat Routes
在 TanStack Router 中,Flat Routes (扁平路由) 是一种通过文件名中的特殊分隔符(如 .)来表达路由层级,而不是依赖物理文件夹层级的方案。
它是 TanStack Router v1.0 之后的推荐趋势。
1. 什么是 Flat Routes?
在 Flat Routes 模式下,你不需要一层套一层的文件夹。你直接在 routes/ 根目录下创建文件,用点 . 来代表路径分隔符。
对比示例:
文件夹模式 (Folder-based):
routes/dashboard/index.tsxroutes/dashboard/settings.tsxroutes/dashboard/profile.tsx
Flat Routes 模式:
routes/dashboard.index.tsxroutes/dashboard.settings.tsxroutes/dashboard.profile.tsx
2. 扁平路由用的多吗?
非常多,甚至正在成为主流。
TanStack Router 的官方 CLI 工具和示例代码现在默认倾向于使用这种扁平化结构。原因在于:
- 文件查找极快:所有路由文件都在一个列表里,一眼就能看到项目有多少个页面,不需要反复展开/折叠多层文件夹。
- 避免“Index 泥潭”:在文件夹模式下,你会有一堆名为
index.tsx的文件,在编辑器标签页里很难分辨。扁平模式下,文件名就是完整路径(如dashboard.settings.tsx),非常清晰。
3. Flat Routes vs. 文件夹模式:深度对比
| 维度 | 文件夹模式 (Directory) | Flat Routes (扁平) |
|---|---|---|
| 可读性 | 适合深度嵌套的超大型项目 | 适合大多数项目,路径清晰 |
| 开发体验 | 编辑器里会出现很多 index.tsx | 每个文件名都是唯一的,好搜索 |
| 移动文件 | 移动文件夹会影响一大片路由 | 修改文件名即可重构路由,风险低 |
| 代码组织 | 可以把组件、样式放在同名文件夹下 | 路由文件只存路由,组件建议放外面 |
4. 哪个更好一些?
这取决于你的代码组织习惯:
选 Flat Routes (推荐) 如果:
- 你讨厌在 VS Code 里点开五层文件夹才找到文件。
- 你希望通过文件名就能定位路由逻辑。
- 你遵循“路由文件只负责逻辑, UI 组件放在外部
components/文件夹”的规范。
选 文件夹模式 如果:
- 你喜欢“就近原则”(Colocation),即把当前页面专用的
Button.tsx、styles.css直接丢在对应的路由文件夹里。 - 你的项目层级极深(例如超过 5 层),文件名可能会变得非常长(如
admin.settings.users.profile.details.tsx)。
5. 混合模式 (Hybrid)
实际上,TanStack Router 支持混合使用。你可以在 routes/ 下用扁平化命名处理简单路由,对于复杂的模块(比如有大量私有组件的 Dashboard),再开一个文件夹。
总结建议
对于新项目,强烈建议优先使用 Flat Routes。它配合你之前问的 _(前缀/后缀)能组合出非常灵活的方案:
_auth.login.tsx(Pathless 布局 + 扁平路径)dashboard_.billing.tsx(打破嵌套的扁平路径)
Dynamic Path Segments
Route segments with the $ token are parameterized and will extract the value from the URL pathname as a route param.
在 TanStack Router 中,Dynamic Path Segments(动态路径段) 是处理 URL 变量(如 ID、用户名等)的核心机制。它允许你通过定义通配符来匹配不同的路径。
在文件路由中,动态段的主要标志是 $ 符号。
1. 基础语法:使用 $
当你希望 URL 中的某一部分是变动的时候,就在文件名或文件夹名中使用 $。
- 文件结构:
routes/posts.$postId.tsx - 匹配 URL:
/posts/1、/posts/abc、/posts/hello-world - 解析结果:
postId的值分别为1、abc、hello-world。
2. 在代码中获取参数
定义了动态路由后,你需要通过 TanStack Router 提供的 Hook useParams 来获取具体的值。
xxxxxxxxxx121import { createFileRoute } from '@tanstack/react-router'23export const Route = createFileRoute('/posts/$postId')({4 component: PostComponent,5})67function PostComponent() {8 // 获取动态参数9 const { postId } = Route.useParams()10 11 return <div>当前浏览的帖子 ID 是: {postId}</div>12}3. 三种常见的动态段类型
① 单个段 (Single Segment)
- 文件名:
users.$userId.tsx - 匹配:
/users/123 - 说明:只匹配路径中的这一层。
② 多个段 (Multiple Segments)
- 文件名:
blog.$categoryId.$postId.tsx - 匹配:
/blog/tech/how-to-code - 说明:你可以同时获取
categoryId和postId。
4. 动态段与类型安全(TanStack Router 的杀手锏)
与其他路由库(如 React Router)不同,TanStack Router 的动态段是全自动类型化的。
- 如果你在文件名里写了
$postId,你在代码里调用useParams()时,编辑器会自动补全postId。 - 如果你尝试访问一个不存在的参数(比如
data.id),TypeScript 会直接报错。
5. 进阶:在 Loader 中使用动态段
动态段最常用的场景是在 loader 中获取数据。例如根据 ID 从 API 请求数据:
xxxxxxxxxx31export const Route = createFileRoute('/posts/$postId')({2 loader: ({ params }) => fetchPost(params.postId), // params 自动包含 postId3})6. Link标签使用params参数传参
Link的to参数,还是写成定义的路由地址那样/posts/$postId,使用params来传递参数。
xxxxxxxxxx21<Link to="/posts/$slug" params={{ postId: 1 }}>2</Link>上面这种方式主要是为了类型安全,也可以直接在to参数上拼接来传参。
Catch-All Routes
在 TanStack Router 中,Catch-All Routes(全匹配路由 / 通配符路由) 用于匹配 URL 中剩余的所有路径部分。当你无法预知路径有多少层级,或者想要捕获所有错误的路径时,这个功能非常有用。
在文件路由中,Catch-All 的核心标志是单个美金符号 $(不带任何名称)。
1. 语法与命名规则
在扁平路由(Flat Routes)或文件夹路由中,你只需要将文件命名为 $.tsx。
文件路径:
routes/docs.$.tsx匹配情况:
/docs/intro(匹配)/docs/setup/installation/windows(匹配)/docs(不一定匹配,通常需要docs.index.tsx处理根路径)
2. 如何获取匹配到的路径值?
由于 Catch-All 匹配的是“剩余的所有部分”,TanStack Router 会将匹配到的路径以字符串的形式存储在 params 中,属性名固定为 _ (下划线)。
xxxxxxxxxx181import { createFileRoute } from '@tanstack/react-router'23export const Route = createFileRoute('/docs/$')({4 component: DocComponent,5})67function DocComponent() {8 // 注意:属性名是下划线 "_"9 const { _ } = Route.useParams()10 11 return (12 <div>13 <h1>文档查看器</h1>14 <p>当前匹配的完整路径是: {_}</p> 15 {/* 如果访问 /docs/a/b/c,则 _ 的值是 "a/b/c" */}16 </div>17 )18}3. Catch-All 的常见用途
① 404 页面(NotFound)
这是最常见的用途。在 routes/ 根目录下创建一个 $.tsx,它会捕获所有无法匹配到已有路由的请求。
routes/$.tsx-> 匹配任何未定义的 URL,展示 404 UI。
② 层次结构不固定的文件管理器
如果你在做一个类似百度网盘或 GitHub 的文件浏览器,路径深度是动态的:
routes/storage/$.tsx- URL:
/storage/work/projects/2024/plan.pdf params._的值就是work/projects/2024/plan.pdf。你可以根据这个字符串去后端查询文件。
4. 优先级与匹配规则
TanStack Router 的路由匹配遵循 “最具体优先” 原则:
- 静态路由 (
routes/about.tsx) 优先级最高。 - 动态段 (
routes/posts.$id.tsx) 优先级次之。 - Catch-All (
routes/$.tsx) 优先级最低,只有在前两者都匹配失败时才会被触发。
Optional Parameters
在 TanStack Router 的 file-based routing 中,{-$locale}.archive.{-$year}.{-$month}.{-$day}.tsx这种写法属于 非常典型的“多段动态路径 + 可选参数” 的文件命名方式。它通常用于实现带日期和语言的博客/文章/新闻归档路由,是非常常见的真实项目写法。
这个文件名到底匹配什么 URL?它会匹配下面这种结构的 URL:
xxxxxxxxxx51/zh/archive/2024/12/252/en/archive/2025/01/013/ja/archive/2023/08/154/archive/2025/03/07 ← 没有语言部分也可以(视配置)5/zh-hant/archive/2024/11/11简单说就是:
xxxxxxxxxx11可选的语言前缀 / archive / 年 / 月 / 日各部分具体含义
| 写法 | 含义 | 是否必须 | 在 URL 中的表现 | 取参方式 |
|---|---|---|---|---|
| {-$locale} | 可选的语言/地区前缀 | 可选 | 最前面一段(如果有) | useParams().locale |
| archive | 固定的路径段(字面量) | 必须 | 永远是 /archive | — |
| {-$year} | 4位年份(通常是数字) | 可选 | 年份那一段 | useParams().year |
| {-$month} | 2位月份 | 可选 | 月份那一段 | useParams().month |
| {-$day} | 2位日期 | 可选 | 日期那一段 | useParams().day |
几种常见的实际匹配例子
| URL 例子 | 能匹配到这个文件吗? | 得到的 params 对象大概是 |
|---|---|---|
| /archive/2025/12/25 | 是 | { year: "2025", month: "12", day: "25" } |
| /en/archive/2024/10/01 | 是 | { locale: "en", year: "2024", ... } |
| /zh-hans/archive/2023/08/19 | 是 | { locale: "zh-hans", year: "2023", ... } |
| /archive/2025 | 通常不会 | (因为后面还缺 month 和 day) |
| /archive/2025/12 | 通常不会 | (缺 day) |
| /fr/blog/2025/12/25 | 不会 | (archive 不匹配) |
为什么前面要加 -?(非常重要的细节)
TanStack Router 的动态参数有两种写法:
xxxxxxxxxx21$year.tsx ← 普通动态参数(必须存在)2{-$year}.tsx ← 可选动态参数(这一段可以不存在)- 的作用就是让这个路径段变成可选。所以 {-$locale}.archive.{-$year}.{-$month}.{-$day}.tsx 的意思是:
前面的语言和后面的年/月/日 都可以不存在,只要中间有 /archive 就行(但实际项目里通常会搭配 loader 来做更严格的验证)
范例代码:
xxxxxxxxxx1151// routes/{-$locale}.archive.{-$year}.{-$month}.{-$day}.tsx23import { createFileRoute } from '@tanstack/react-router'4import { useSuspenseQuery } from '@tanstack/react-query'5import { format, parse } from 'date-fns'6import { zhCN, enUS, ja } from 'date-fns/locale'78// 假设你有这样的文章数据获取函数9import { getPostsByDate } from '@/lib/api/posts'1011export const Route = createFileRoute('/archive')({12 // 可选:定义更严格的 params 解析规则(推荐)13 parseParams: (params) => ({14 locale: params.locale || 'en', // 默认语言15 year: params.year ? Number(params.year) : undefined,16 month: params.month ? Number(params.month) : undefined,17 day: params.day ? Number(params.day) : undefined,18 }),1920 stringifyParams: ({ locale, year, month, day }) => ({21 (locale !== 'en' && { locale }),22 (year && { year: String(year) }),23 (month && { month: String(month).padStart(2, '0') }),24 (day && { day: String(day).padStart(2, '0') }),25 }),2627 // 核心数据加载逻辑28 loader: async ({ params, context: { queryClient } }) => {29 const { year, month, day, locale } = params3031 // 根据参数决定查询范围32 let dateFilter:33 | { year: number; month?: number; day?: number }34 | undefined = undefined3536 if (year) {37 dateFilter = { year }38 if (month) {39 dateFilter.month = month40 if (day) dateFilter.day = day41 }42 }4344 return queryClient.ensureQueryData({45 queryKey: ['posts', 'archive', dateFilter, locale],46 queryFn: () => getPostsByDate(dateFilter, locale),47 })48 },4950 // 组件51 component: ArchivePage,52})5354// 日期格式化辅助函数55const getDateTitle = (params: Route['types']['Params']) => {56 const { year, month, day, locale } = params5758 const locales = { 'zh-CN': zhCN, 'en': enUS, 'ja': ja }59 const dateLocale = locales[locale as keyof typeof locales] ?? enUS6061 if (day && month && year) {62 return format(63 new Date(year, month - 1, day),64 'PPP', // e.g. Dec 25th, 202565 { locale: dateLocale }66 )67 }68 if (month && year) {69 return format(new Date(year, month - 1), 'MMMM yyyy', { locale: dateLocale })70 }71 if (year) {72 return String(year)73 }74 return 'All Archives'75}7677function ArchivePage() {78 const { locale = 'en', year, month, day } = Route.useParams()7980 const { data: posts = [] } = useSuspenseQuery(81 Route.useQueryOptions() // 自动使用上面 loader 的 queryKey & queryFn82 )8384 const title = getDateTitle({ locale, year, month, day })8586 return (87 <div className="container mx-auto py-12">88 <h1 className="text-4xl font-bold mb-8">89 {title} {locale !== 'en' && `(${locale.toUpperCase()})`}90 </h1>9192 {posts.length === 0 ? (93 <p className="text-muted-foreground">No posts found for this period.</p>94 ) : (95 <div className="grid gap-8 md:grid-cols-2 lg:grid-cols-3">96 {posts.map((post) => (97 <article key={post.id} className="border rounded-lg p-6 hover:shadow-md transition">98 <time className="text-sm text-muted-foreground">99 {format(new Date(post.date), 'PPP')}100 </time>101 <h2 className="text-xl font-semibold mt-2">102 <Link to="/posts/$slug" params={{ slug: post.slug }}>103 {post.title}104 </Link>105 </h2>106 <p className="mt-2 text-muted-foreground line-clamp-2">107 {post.excerpt}108 </p>109 </article>110 ))}111 </div>112 )}113 </div>114 )115}Search Parameters
在 TanStack Router 中,Search Parameters(查询参数,即 URL 中 ? 后面的部分) 被提升到了“一等公民”的地位。
与传统的路由库不同,TanStack Router 要求你对查询参数进行显式验证和类型定义。这意味着你可以像处理组件的 Props 一样,以类型安全的方式处理 URL 参数。
1. 核心流程:验证与定义
要使用 Search Params,你必须在定义路由时使用 validateSearch 函数。
xxxxxxxxxx181// routes/users.tsx2import { createFileRoute } from '@tanstack/react-router'34// 2. 在路由中引用5export const Route = createFileRoute('/users')({6 component: UserComponent,7 // 验证函数:如果验证通过,返回的数据就是强类型的8 validateSearch: (search: Record<string, unknown>) => {9 return {10 page: (search.page as number),11 sort_by: (search.sort_by as string) || "",12 } 13 },14 // 在 Loader 中也可以直接拿到强类型的 params15 loader: ({ search }) => {16 console.log(search.page) // 这里 search.page 自动就是 number 类型17 }18})2. 为什么这样做?(三大优势)
- 类型安全:当你使用
useSearch()钩子时,你拿到的page是真正的number类型,而不是字符串。 - 运行时纠错:如果用户手动在地址栏输入了非法的参数(例如
?page=abc),fallback或验证逻辑会自动修正它,防止页面崩溃。 - Link 跳转保护:当你使用
<Link to="/users" search={{ page: 2 }} />时,IDE 会自动补全参数名;如果你漏写了必填参数,代码会报错。
3. 如何在代码中使用
获取参数:useSearch
xxxxxxxxxx41function UsersComponent() {2 const { page, filter } = Route.useSearch()3 return <div>当前页码:{page}</div>4}修改参数:useNavigate 或 <Link>
改变 Search Params 通常用于分页、排序和搜索过滤。
xxxxxxxxxx81const navigate = useNavigate({ from: Route.fullPath })23// 更新参数而不丢失其他参数4const handlePageChange = (newPage: number) => {5 navigate({6 search: (prev) => ({ prev, page: newPage }),7 })8}4. Search Params vs Path Params
| 特性 | Path Params ($id) | Search Params (?page=1) |
|---|---|---|
| 定位 | 标识资源本身 (Identity) | 改变资源的呈现方式 (State) |
| 必要性 | 通常是必须的 | 通常是可选的或有默认值 |
| 类型 | 总是字符串 | 可以通过验证器转为数字、布尔、对象等 |
| SEO | 权重高,路径清晰 | 权重较低,适合过滤和排序 |
5. 进阶:JSON 状态压缩
TanStack Router 支持将复杂的对象甚至数组放入 Search Params。它会自动处理序列化和反序列化,让你可以直接在 URL 中存储像 ?filters={"status":["active","pending"]} 这样的复杂状态。
例子:
xxxxxxxxxx131<Link to="/products" search={{2 sort_by: "price",3 product_type: ["shoes", "t-shirts"],4 pagination: {5 page: 1,6 pageSize: 107 },8 colors: ["red", "blue"],9 sale: true10 }}11>12 Products with Filters13</Link>总结
在 TanStack Router 中,Search Params 不再是“杂乱的字符串”。通过 validateSearch,你把 URL 变成了一个类型安全的全局状态管理器。
Validating Search Params with Zod
虽然可以自己写search params的校验逻辑,但是结合zod使用就非常高效。
安装依赖pnpm add @tanstack/zod-adapter。
在 TanStack Router 中使用 Zod 校验 Search Params,本质上是把 URL 字符串 变成 结构化的 TypeScript 对象。
当你访问 ?page=1&filter=react 时,浏览器只知道它们是字符串。Zod 的作用就是解析、转换并确保这些数据的安全。
一个典型的校验逻辑拆解,比如说url是这样的/search?page=1&criteria={"query":"laptop","range":{"min":1000,"max":5000}}&tags=electronics&tags=sale。
第一步:定义zod schema
xxxxxxxxxx201import { z } from 'zod'23const searchSchema = z.object({4 // 1. 基础字段5 page: z.coerce.number().catch(1),67 // 2. 嵌套对象:搜索标准8 criteria: z.object({9 query: z.string().default(''),10 range: z.object({11 min: z.number().catch(0),12 max: z.number().catch(99999),13 }).default({ min: 0, max: 99999 })14 }).default({ query: '', range: { min: 0, max: 99999 } }),1516 // 3. 数组字段:多选标签17 tags: z.array(z.string()).catch([]),18});1920type SearchParams = z.infer<typeof searchSchema>;常见转换方法:
| Zod 方法 | 处理 URL 时的作用 |
|---|---|
z.coerce.number() | 把字符串 "10" 变成数字 10 |
z.coerce.boolean() | 把字符串 "true" 变成布尔值 true |
.default(val) | 如果 URL 没传这个 key,就填入默认值 |
.catch(val) | 最推荐。如果用户传错了,就填入默认值,防止页面挂掉 |
.transform() | 进一步处理数据,比如把 "2024-01-01" 转为 Date 对象 |
第二步:配置路由与 Loader
在这里,Loader 会直接拿到经过 Zod 清洗后的数据,直接发送给 API。
可以看到,validateSearch里面就很简单了。
xxxxxxxxxx251import { createFileRoute } from '@tanstack/react-router'2import { zodValidator } from '@tanstack/zod-adapter'34const searchSchema56type SearchParams78export const Route = createFileRoute('/_admin/products')({9 // 1. 验证查询参数10 validateSearch: zodValidator(productSearchSchema),1112 // 2. 预加载数据:search 参数已经是强类型的了13 loader: ({ search }) => {14 // 假设这是一个从后台获取数据的函数15 return fetchProducts({16 page: search.page,17 q: search.filter,18 tags: search.categories,19 sort: search.sort,20 includeArchived: search.showArchived21 })22 },23 24 component: ProductsPage,25})第三步:组件内的交互
展示如何使用 useSearch 获取状态,以及如何通过 useNavigate 修改状态。
xxxxxxxxxx461function ProductsPage() {2 const { page, filter, categories, sort } = Route.useSearch()3 const navigate = useNavigate({ from: Route.fullPath })4 const products = Route.useLoaderData()56 // 修改排序的函数7 const updateSort = (newSort: string) => {8 navigate({9 search: (prev) => ({ prev, sort: newSort as any, page: 1 }),10 })11 }1213 // 切换分类的函数(处理数组)14 const toggleCategory = (cat: string) => {15 const nextCategories = categories.includes(cat)16 ? categories.filter((c) => c !== cat)17 : [categories, cat]18 19 navigate({20 search: (prev) => ({ prev, categories: nextCategories, page: 1 }),21 })22 }2324 return (25 <div>26 <h1>商品管理 ({page})</h1>27 28 {/* 搜索框 */}29 <input 30 value={filter ?? ''} 31 onChange={(e) => navigate({ search: (prev) => ({ prev, filter: e.target.value || undefined }) })}32 />3334 {/* 排序下拉 */}35 <select value={sort} onChange={(e) => updateSort(e.target.value)}>36 <option value="newest">最新上架</option>37 <option value="price_asc">价格从低到高</option>38 </select>3940 {/* 列表渲染 */}41 <ul>42 {products.map(p => <li key={p.id}>{p.name} - ${p.price}</li>)}43 </ul>44 </div>45 )46}- 这个“复杂”例子的核心亮点
- 数据过滤逻辑高度一致:由于采用了
validateSearch,用户无论是在搜索框输入、点击分页、还是点击浏览器后退按钮,页面拿到的search对象格式永远是一致且安全的。 - Loader 自动触发:只要 URL 里的
page或filter变了,TanStack Router 就会自动重新调用 Loader 获取新数据。你不需要写任何useEffect来监听参数变化。 - URL 是唯一的真理 (Single Source of Truth):整个页面的过滤、排序状态完全由 URL 决定。你可以直接把当前的链接发给同事,他打开看到的页面和你一模一样。
- Zod 的预处理 (
preprocess):在处理布尔值(如showArchived)时,URL 里是字符串"true",Zod 自动将其转成了 JavaScript 的true。
Zod 在路由生命周期中的位置
TanStack Router 保证了在你的组件渲染之前,数据就已经通过了 Zod 的检查。
- 输入:浏览器地址栏原始字符串
?page=5&view=grid。 - 校验层 (
validateSearch):Zod 运行parse()。它检查page是否能转成数字,view是否在枚举里。 - 输出:一个干净的 JavaScript 对象
{ page: 5, view: 'grid' }。 - 消费:你的组件通过
Route.useSearch()直接拿到这个对象,类型提示是完美的。
Handling Search Params Errors
如果用户输入了错入的url地址,该怎么处理呢?
在 TanStack Router 中,Zod 的错误处理主要分为两个层面:Schema 内部的“自动纠错”和路由层面的“全局拦截”。
1. 第一道防线:Zod 内部的“软处理” (推荐)
这是最常用的方式,通过在 Schema 中定义“后路”,确保即使用户输入错误,应用也不会挂掉。
A. 使用 .catch() (最强纠错)
无论发生什么错误(解析失败、类型不符、为空),都返回一个指定的默认值。
xxxxxxxxxx41const schema = z.object({2 // 如果 URL 是 ?page=hello,page 会自动变成 13 page: z.coerce.number().catch(1), 4})B. 使用 .default() (处理缺失)
只在 URL 中缺少该参数时生效。
xxxxxxxxxx41const schema = z.object({2 // URL 没有 page 参数时为 1;如果有 page=abc,校验依然会报错3 page: z.coerce.number().default(1), 4})C. 结合使用
通常建议这样写,既能处理缺失,也能处理错误:
xxxxxxxxxx11page: z.coerce.number().catch(1) // 只要不是数字,通通变回 1D. 使用fallback处理
fallback 函数通常是从 @tanstack/react-router 中导出的,专门用于 validateSearch 阶段。
xxxxxxxxxx141import { fallback } from '@tanstack/react-router'2import { z } from 'zod'34export const Route = createFileRoute('/search')({5 validateSearch: (search) => {6 return {7 // 使用 fallback 函数8 query: fallback(z.string(), 'default-query').parse(search.query),9 10 // 或者在对象里配合使用11 page: fallback(z.number(), 1).parse(search.page),12 }13 },14})fallback,catch二者选择一种就行了,千万不要混着使用,因为二者效果是一致的,混着使用代码可读性非常差。
2. 第二道防线:路由层面的“硬拦截”
如果你没有在 Zod Schema 中写 .catch(),那么当 Zod 校验失败(.parse() 抛出异常)时,TanStack Router 会启动错误流程。
A. 触发 errorComponent
如果 validateSearch 抛出错误,该路由的 errorComponent 会被渲染。你可以在这里给用户展示一个“搜索条件错误”的提示。
xxxxxxxxxx71export const Route = createFileRoute('/products')({2 validateSearch: zodValidator(productSearchSchema),3 // 当 Zod 报错时,渲染这个组件4 errorComponent: ({ error }) => {5 return <div>输入的搜索参数不对哦:{error.message}</div>6 },7})B. 拦截重定向
你也可以在校验失败时,强行把用户踢回正确的 URL。
xxxxxxxxxx131export const Route = createFileRoute('/products')({2 validateSearch: (search) => {3 try {4 return productSearchSchema.parse(search)5 } catch (e) {6 // 发现错误,直接重定向到第一页7 throw redirect({8 to: '/products',9 search: { page: 1 },10 })11 }12 },13})3. Zod 错误处理的底层逻辑图
用户修改 URL -> 2.
validateSearch执行 -> 3. Zod 校验:- 成功 -> 进入
loader-> 渲染组件。 - 失败 (有
.catch) -> 修正数据 -> 进入loader-> 渲染组件。 - 失败 (无
.catch) -> 抛出异常 -> 寻找最近的errorComponent或跳转。
- 成功 -> 进入
4. 进阶:如何自定义 Zod 报错信息?
有时候你想在 UI 上精确显示哪个字段错了,可以利用 Zod 的 errorMap 或者简单的 try-catch。
xxxxxxxxxx61const productSearchSchema = z.object({2 page: z.coerce.number({3 invalid_type_error: "页码必须是数字",4 required_error: "页码不能为空"5 }),6})5. 总结:最佳实践建议
对于分页、排序、筛选:一律使用
.catch()。- 原因:用户手动改 URL 很正常,不应该因为一个参数错了就让整个页面崩溃(显示报错页面)。让他们回到默认状态是最好的体验。
对于关键性业务参数:不使用
.catch(),让它抛错。- 原因:比如一个加密的校验 Token,如果错了,就应该明确显示“链接已失效”。
使用
zodValidator:它会自动处理 Zod 的ZodError对象,并将其传递给errorComponent,让你能拿到详细的错误数组(哪些字段错了,原因是什么)。
More on the Link Component
1. 强类型的参数检查 (Type-Safe Params & Search)
这是 TanStack Router 最核心的优势。如果你定义的路由有动态参数或查询参数,<Link> 会强制要求你提供它们,否则代码无法通过编译。
- 路径参数:如果去往
/posts/$postId,你必须传params。 - 查询参数:如果
/users路由有validateSearch,你必须传search。
xxxxxxxxxx81// 自动补全和类型检查2<Link 3 to="/posts/$postId" 4 params={{ postId: '123' }} 5 search={{ showDetails: true }}6>7 查看文章8</Link>2. 智能预加载 (Intent-based Preloading)
TanStack Router 可以在用户真正点击链接之前就加载好数据(Loader)。
preload: 'intent'(默认/推荐):当用户鼠标悬停 (Hover) 在链接上,或者手指按住链接时,后台会立即开始执行该路由的loader。preload: 'render':只要链接出现在屏幕上,就立即预加载。
xxxxxxxxxx71<Link 2 to="/dashboard" 3 preload="intent" 4 preloadDelay={50} // 悬停 50ms 后触发5>6 后台管理7</Link>效果:用户点击时,数据通常已经加载好了,页面秒开。
3. 函数式更新 Search Params
当你只想修改当前 URL 的一个查询参数(例如分页),而不影响其他参数时,可以使用函数写法。这避免了手动合并复杂的 search 对象。
xxxxxxxxxx161<Link2 // 1. 明确告诉 Link,我从当前路由“这里”出发3 from={Route.fullPath}4 5 // 2. 不写 to,意味着目标就是“这里”6 7 // 3. 这里的 prev 就会被正确推导为当前路由的 Search Params 类型8 search={(prev) => ({ 9 prev, 10 pagination: {11 prev.pagination,12 page: (prev.pagination?.page || 1) + 1,13 } })} // 仅修改 page14>15 下一页16</Link>4. 动态 Active 状态处理
你可以根据链接是否处于激活状态(Active)来应用不同的样式或组件。
activeProps:激活时的样式属性。inactiveProps:未激活时的样式属性。children函数:根据激活状态渲染不同的内容。
xxxxxxxxxx111<Link2 to="/settings"3 activeProps={{ className: 'font-bold text-blue-600' }}4 inactiveProps={{ className: 'text-gray-500' }}5>6 {({ isActive }) => (7 <>8 设置 {isActive && <StarIcon />}9 </>10 )}11</Link>5. Data 属性与 View Transitions
你可以配合浏览器原生的 View Transitions API 实现平滑的页面过渡效果。
xxxxxxxxxx61<Link2 to="/profile"3 viewTransition // 开启视图过渡动画4>5 个人主页6</Link>6. 遮罩跳转 (Masking URL)
有时候你想让用户跳转到某个路由,但在地址栏显示另一个更美观的地址。
xxxxxxxxxx71<Link2 to="/photos/$photoId"3 params={{ photoId: '5' }}4 mask={{ to: '/photos/view' }} // 实际上地址栏会显示 /photos/view5>6 查看图片7</Link>总结:Link 的高级特性对比
| 特性 | 作用 | 带来的好处 |
|---|---|---|
| Type Safety | 编译时检查 to, params, search | 减少运行时错误,重构更放心 |
| Preloading | hover 时预取数据 | 极致的性能体验,消除加载白屏 |
| Search Function | (prev) => ({...}) | 简化复杂筛选、分页的逻辑 |
| Active States | 内置 isActive 逻辑 | 轻松实现复杂的导航 UI |
如果我使用了tanstack/router,也使用了tanstack/table,我该怎么处理分页和搜索呢?
将 Table 的状态(分页、排序、过滤)“同步”到 URL 中。url长度是有限的,只要不超过这个限制,就没有问题。
不要在表格组件里使用
useState来维护pageIndex或globalFilter,而是:
- 从 URL 读取状态(通过
useSearch)。- 将状态传给 Table(作为
state属性)。- 在 Table 变化时更新 URL(通过
onStateChange触发Maps)。
Other ways to Navigate Programmatically
1. 使用 useNavigate Hook (最常用)
这是在组件内部进行逻辑跳转的标准方式。它返回一个 Maps 函数,支持与 <Link> 完全相同的类型安全参数。
xxxxxxxxxx131import { useNavigate } from '@tanstack/react-router'23function LoginButton() {4 const navigate = useNavigate()56 const handleLogin = async () => {7 await auth.login()8 // 逻辑执行完后跳转9 navigate({ to: '/dashboard' })10 }1112 return <button onClick={handleLogin}>登录</button>13}高级技巧: 配合 from 属性,你可以像 Link 一样实现 Search Params 的函数式更新。因为from属性指定之后,tanstack会记住当前路由的参数。
xxxxxxxxxx61const navigate = useNavigate({ from: '/products' })23// 仅更新分页,不写 to4navigate({5 search: (prev) => ({ prev, page: prev.page + 1 })6})2. 在 Loader 或 BeforeLoad 中使用 throw redirect
如果你需要在页面渲染 之前 进行拦截并跳转(例如:未登录用户访问后台),你应该使用 redirect 函数。
- 特点:必须使用
throw关键字,这会中断当前的路由解析流程并立即跳转。
xxxxxxxxxx101export const Route = createFileRoute('/admin')({2 beforeLoad: ({ search }) => {3 if (!isAuthenticated()) {4 throw redirect({5 to: '/login',6 search: { redirect: '/admin' }, // 记录来源以便登录后跳回7 })8 }9 },10})3. 使用 router.navigate (全局 API)
如果你在组件外部(例如在 Redux 中、全局拦截器中或普通 JS 函数里),可以通过直接访问 router 实例来进行跳转。
xxxxxxxxxx61import { router } from '../main' // 假设你导出了创建的 router 实例23export function logout() {4 localStorage.removeItem('token')5 router.navigate({ to: '/login' })6}4. 路由跳转方式对比
| 方法 | 使用场景 | 特点 |
|---|---|---|
<Link> | 用户点击 UI 元素 | 支持预加载 (Preload),SEO 友好,首选方式。 |
useNavigate | 事件回调、异步逻辑完成后 | 编程式,支持所有 Link 的类型检查特性。 |
throw redirect | loader 或 beforeLoad 期间 | 在渲染前拦截,常用于权限控制。 |
router.navigate | 组件外部、全局单例 | 适用于非 React 上下文。 |
5. 跳转时的“姿势”控制
在调用跳转方法时,你可以通过一些特殊的属性来控制跳转行为:
replace: true:使用history.replaceState而不是pushState。这不会在浏览器历史记录中留下新条目,常用于搜索过滤。resetScroll: false:跳转后保留滚动位置(默认通常是滚动到顶部)。state:可以传递一些临时的、不显示在 URL 里的状态(通过location.state获取)。
其实还有一个
<Navigate to="">组件可以用来跳转,但是这个组件有一个问题,它是当组件被渲染时,立即触发路由跳转。可能会造成页面闪动、白屏的情况,使用时需注意。
Context
在 TanStack Router 中,Context(上下文) 是一个非常强大的特性,它允许你在路由树中自上而下地传递数据、服务或状态(例如:QueryClient、Auth 信息、主题等)。
1. 核心流程:从根路由开始
Context 的传递通常是从 rootRoute 开始定义的。
第一步:定义 Context 类型
首先,你需要定义一个类型来描述你的上下文包含什么。
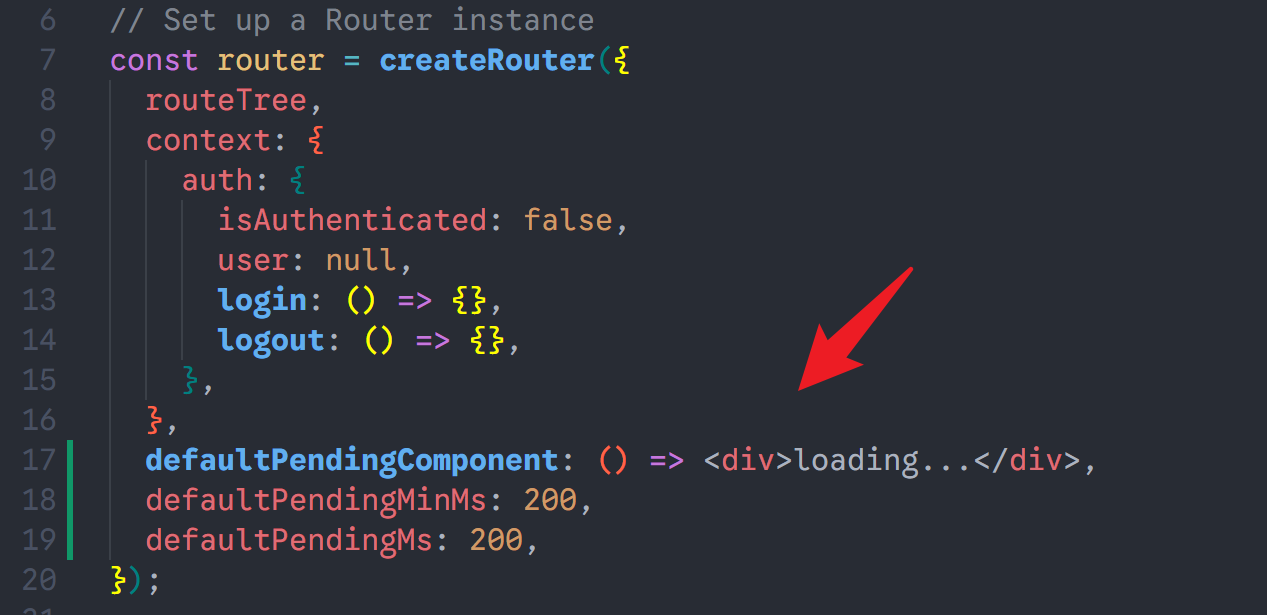
xxxxxxxxxx131// src/routes/__root.tsx23interface MyRouterContext {4 auth: {5 isAuthenticated: boolean6 user: User | null7 }8}910// 创建 rootRoute 时传入类型11export const Route = createRootRouteWithContext<MyRouterContext>()({12 component: RootComponent,13})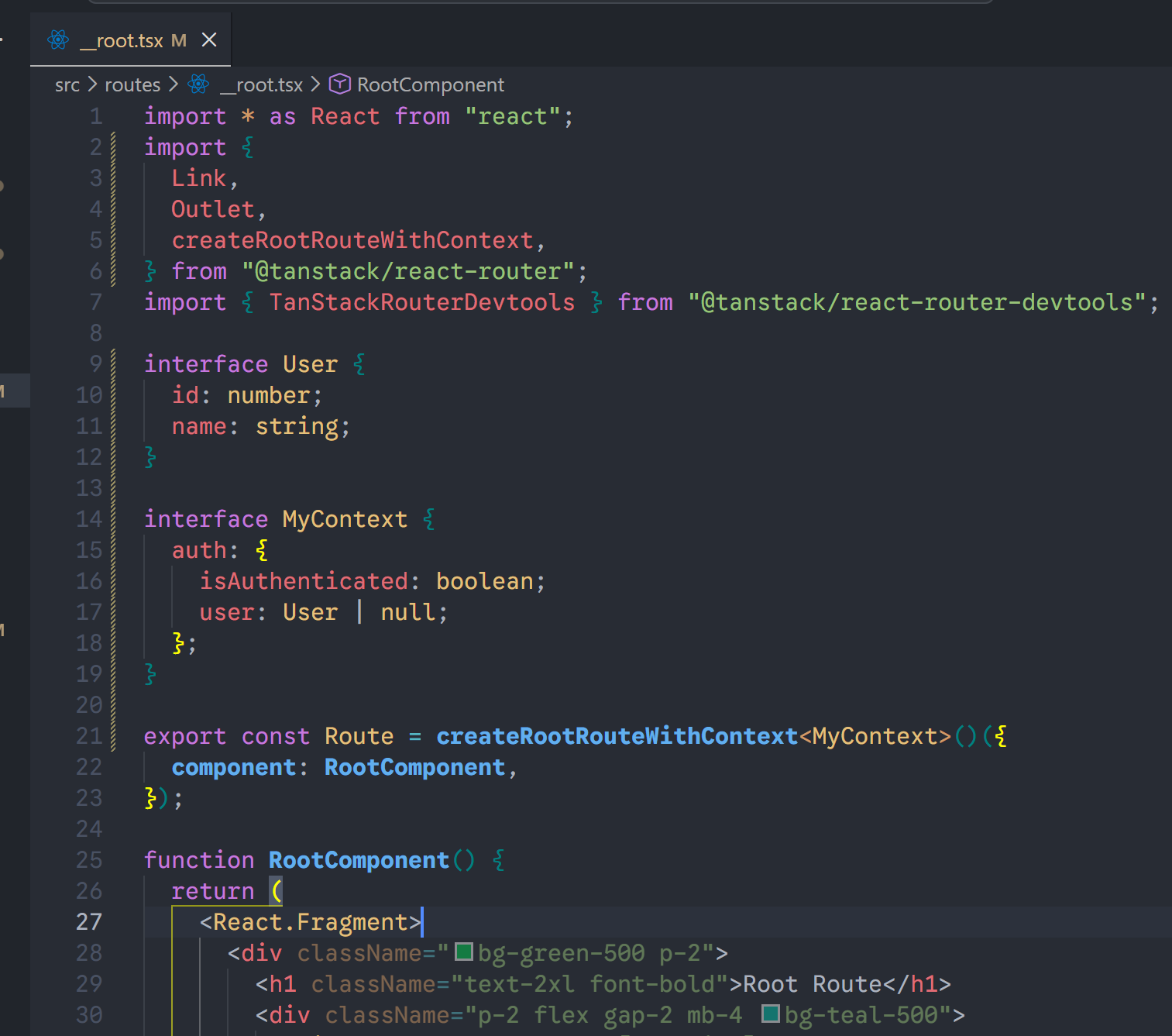
第二步:在创建 Router 时注入具体值
在你的 main.tsx 或 App.tsx 中,你需要把真实的数据传给 createRouter。
xxxxxxxxxx101const router = createRouter({2 routeTree,3 context: {4 // 这里的初值通常是占位符,或者在初始化时确定的值5 auth: {6 isAuthenticated: false,7 user: null,8 }, 9 },10})2. 在子路由中消费 Context
子路由可以通过 beforeLoad 或 loader 访问到这些 Context。
xxxxxxxxxx131export const Route = createFileRoute('/dashboard')({2 // context 包含从父级(如 root)传下来的所有内容3 loader: ({ context }) => {4 // 甚至可以在这里直接使用注入的 queryClient 请求数据5 return context.queryClient.ensureQueryData(productsQueryOptions)6 },7 beforeLoad: ({ context }) => {8 // 权限检查逻辑9 if (!context.auth.isAuthenticated) {10 throw redirect({ to: '/login' })11 }12 },13})3. Context 的“继承与合并”
Context 是可以累加的。父路由可以向下传递 Context,子路由也可以在自己的 beforeLoad 中添加新的 Context 给它的子路由。
- Root Route: 提供
queryClient。 - _auth Layout Route: 在
beforeLoad中获取user详情,并将其加入 Context。 - _auth.profile Route: 此时的 Context 既包含
queryClient也包含user。
xxxxxxxxxx101// _auth.tsx (布局路由)2export const Route = createFileRoute('/_auth')({3 beforeLoad: async ({ context }) => {4 const user = await fetchUser()5 return {6 // 返回的对象会合并到当前及子路由的 context 中7 user, 8 }9 },10})4. 在组件中获取 Context
如果你需要在 UI 组件中访问 Context,可以使用 useContext 钩子(注意:这是 Route 对象自带的钩子)。
xxxxxxxxxx61function ProfileComponent() {2 // 拿到的是整个路由树合并后的完整 Context3 const context = Route.useRouteContext()4 5 return <div>你好, {context.user.name}</div>6}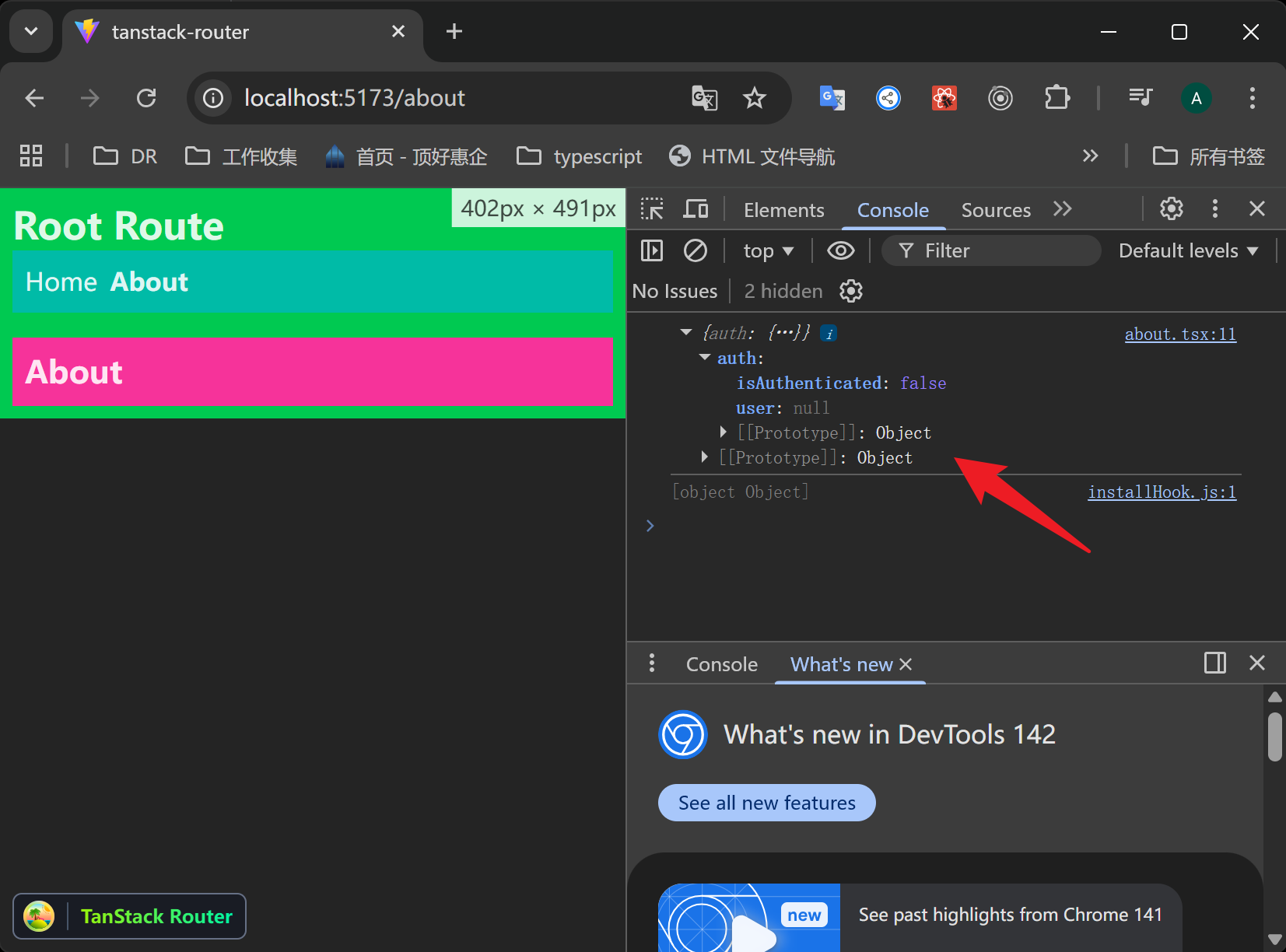
5. 常见实战场景:集成 TanStack Query
这是 Context 最常见的用法。通过将 queryClient 注入 Context,你可以在所有路由的 loader 中预取数据。
TypeScript
xxxxxxxxxx41export const Route = createFileRoute('/posts/$postId')({2loader: ({ context: { queryClient }, params: { postId } }) =>3queryClient.ensureQueryData(postQueryOptions(postId))4})
6. 为什么不用 React Context?
虽然它们名字一样,但 Router Context 有几个独特的优势:
- 非渲染时机访问:React Context 只能在组件渲染时(Hooks)使用,而 Router Context 可以在路由跳转前(
loader/beforeLoad)使用。 - 类型安全:通过
createRootRouteWithContext,整个路由树的 Context 都是强类型的,IDE 会全程提供补全。 - 数据流清晰:它迫使你思考哪些数据是路由级别的(权限、数据客户端),哪些是 UI 级别的。
总结
- 定义:在
rootRoute用createRootRouteWithContext<T>()定义结构。 - 注入:在
createRouter({ context })中传入实例。 - 扩展:在子路由的
beforeLoad返回新对象来增加 Context。 - 消费:在
loader/beforeLoad直接解构,或在组件用useContext()。
Passing State in Context
在 TanStack Router 中“传递状态到 Context”:
- 定义:在
RootRoute定义接口。 - 注入:在
App组件中将状态传递过去。 - 消费:在子路由通过
context对象(Loader/BeforeLoad)或useRouteContext()(组件)访问。
1. 模式核心:在根组件中动态更新 Context
你需要在 createRouter 时提供初始结构,然后在 React 根组件渲染时,使用router.invalidate同步状态。
第一步:定义 Context 类型
xxxxxxxxxx141// src/routes/__root.tsx23interface MyContext {4 auth: {5 isAuthenticated: boolean;6 user: User | null;7 login: (user: User) => void;8 logout: () => void;9 };10}1112export const rootRoute = createRootRouteWithContext<MyContext>()({13 component: RootComponent,14})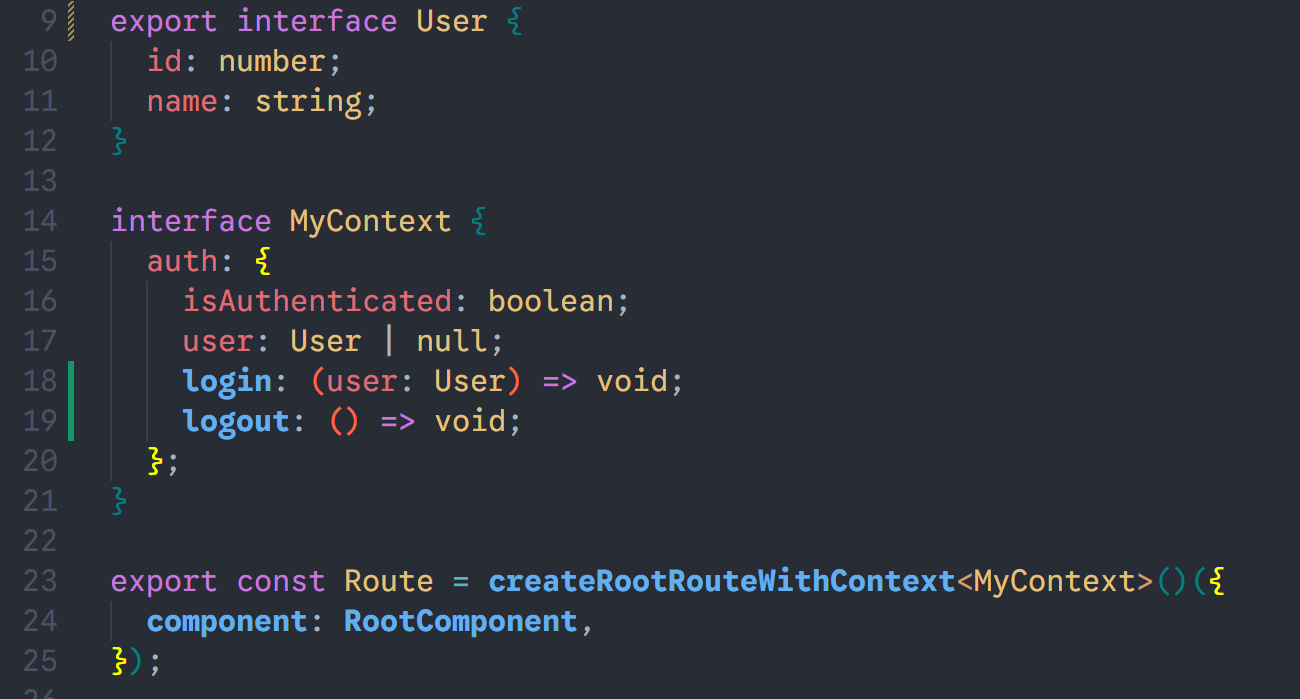
第二步:在 App 组件中注入并同步状态
这是关键点。你可以在顶层组件维护状态,并通过setState方法传递到上下文中,在子组件中可以调用setState来变更状态。
xxxxxxxxxx521// App.tsx2import { createRouter, RouterProvider } from '@tanstack/react-router'34// Set up a Router instance5const router = createRouter({6 routeTree,7 context: {8 auth: {9 isAuthenticated: false,10 user: null,11 login: () => {},12 logout: () => {},13 },14 },15});1617// 创建一个新组件,将状态传递过去18export const InnerApp = () => {19 const [user, setUser] = useState<User | null>(null);2021 useEffect(() => {22 router.invalidate(); // ← 关键!让 router 重新计算 context23 }, [user]); // 依赖 user 变化2425 function login(user: User) {26 setUser(user);27 }2829 function logout() {30 setUser(null);31 }3233 return (34 <RouterProvider35 router={router}36 context={{37 auth: {38 isAuthenticated: false,39 user,40 login,41 logout,42 },43 }}44 />45 );46};4748createRoot(document.getElementById("root")!).render(49 <StrictMode>50 <InnerApp />51 </StrictMode>52);2. 在子路由中消费这个状态
现在,这个状态已经存在于路由树的 Context 中了,你可以跨过组件层级直接使用。
在 beforeLoad 中拦截
xxxxxxxxxx71export const Route = createFileRoute('/admin')({2 beforeLoad: ({ context }) => {3 if (!context.isAuthenticated) {4 throw redirect({ to: '/login' })5 }6 },7})在组件中使用 useRouteContext 的上下文来修改状态
xxxxxxxxxx331function RootComponent() {2 const { auth } = Route.useRouteContext();3 const { user, login, logout } = auth;4 5 return (6 <React.Fragment>7 <div className="bg-green-500 p-2">8 {user ? (9 <>10 <h1 className="text-2xl font-bold">Welcome, {user.name}</h1>11 <button onClick={logout}>logout</button>12 </>13 ) : (14 <>15 <h1 className="text-2xl font-bold">Hello, Guest.Please login.</h1>16 <button17 onClick={() =>18 login({19 id: 1,20 name: "jack",21 })22 }>23 login24 </button>25 </>26 )}27 28 ......29 <TanStackRouterDevtools />30 </div>31 </React.Fragment>32 );33}可以看到,login、logout按钮控制了上下文,这真是好用:
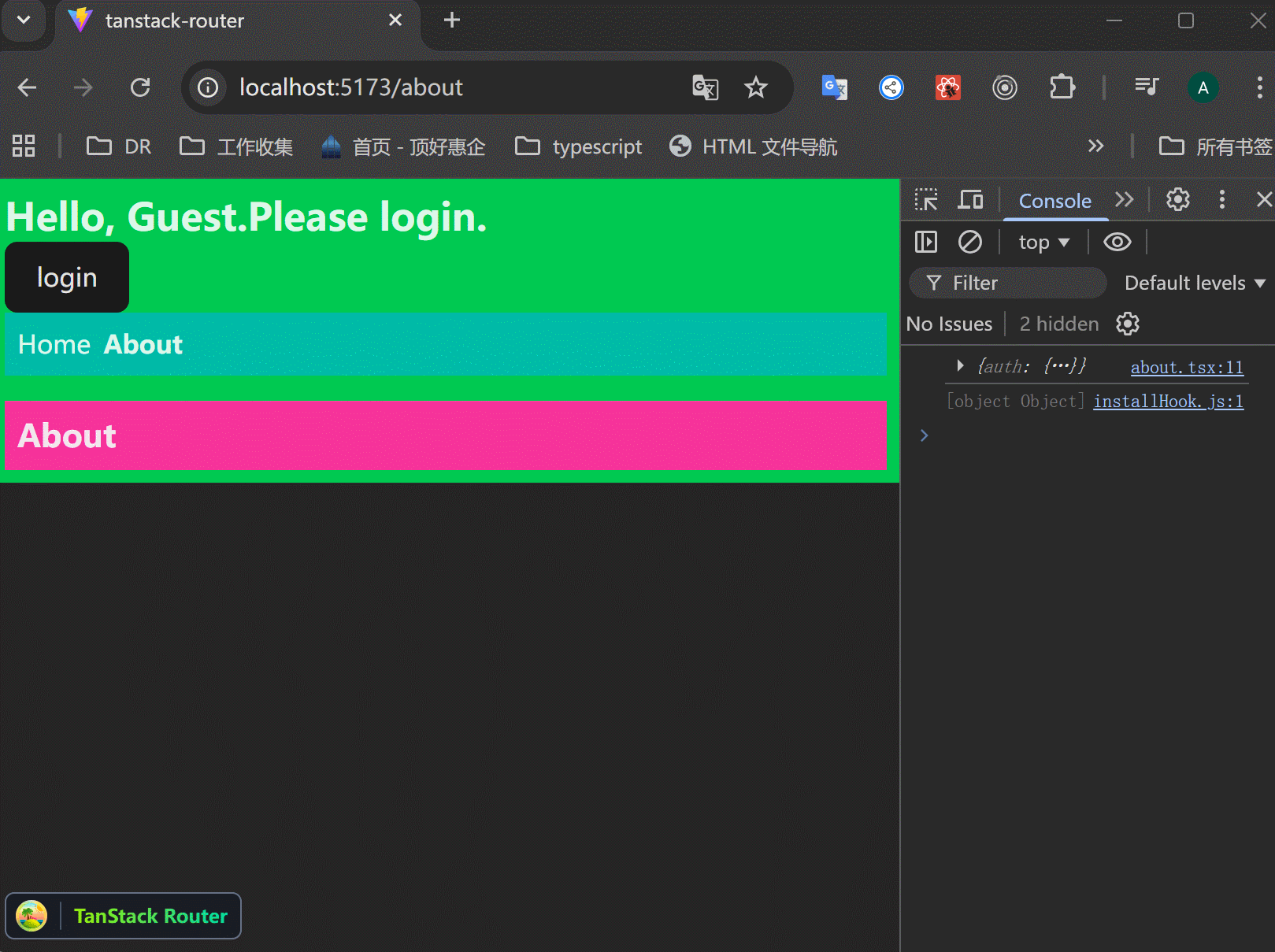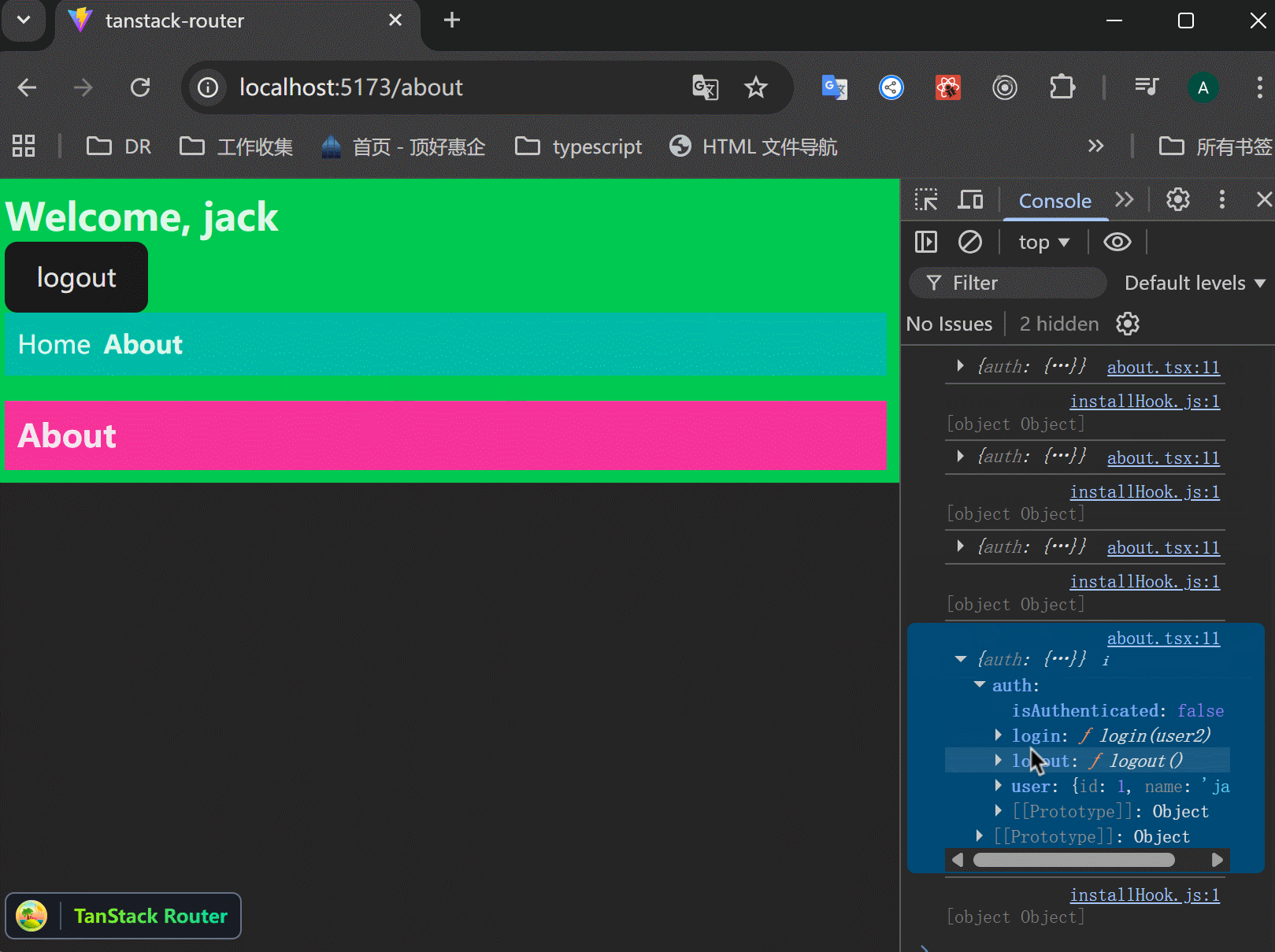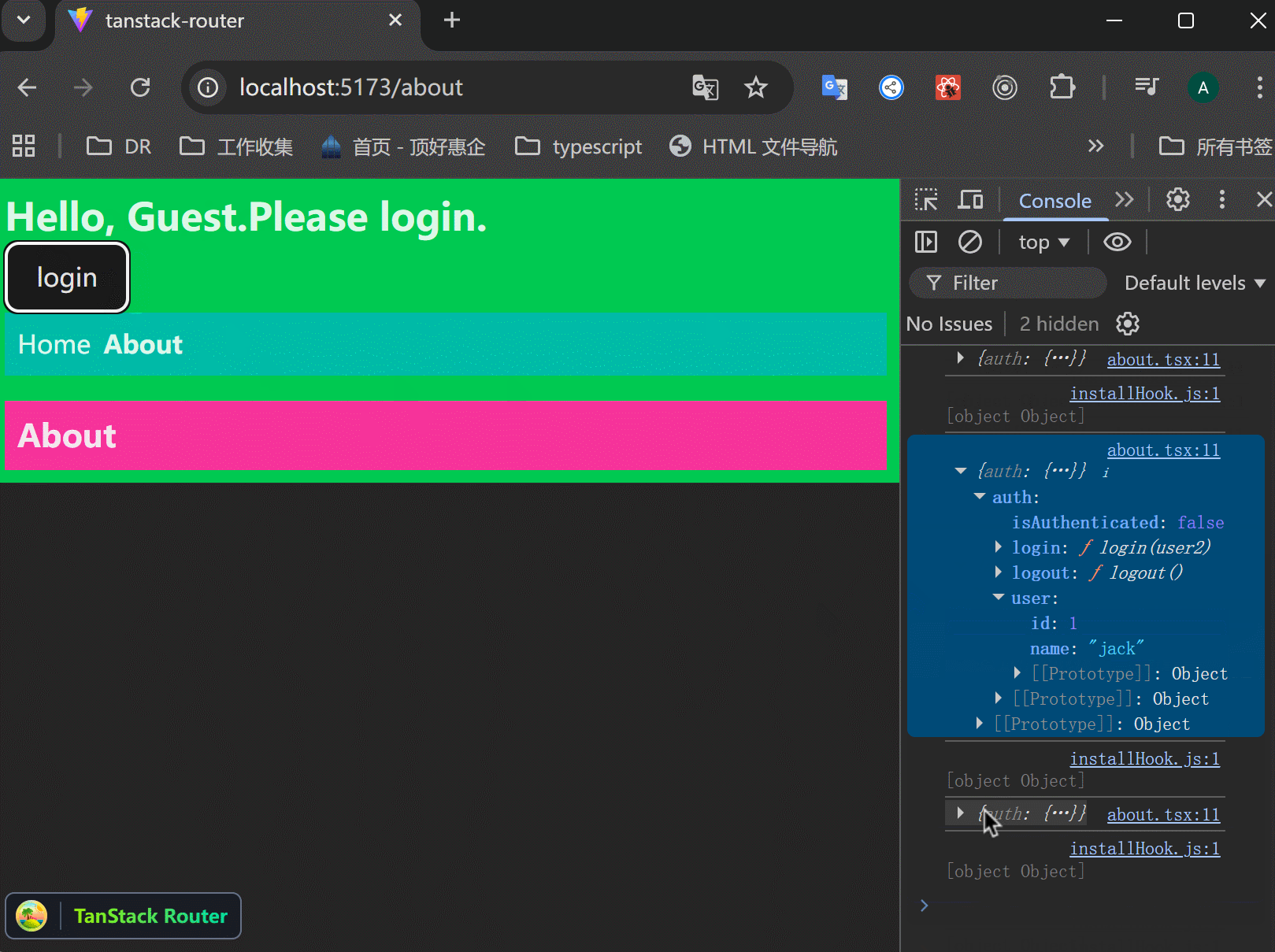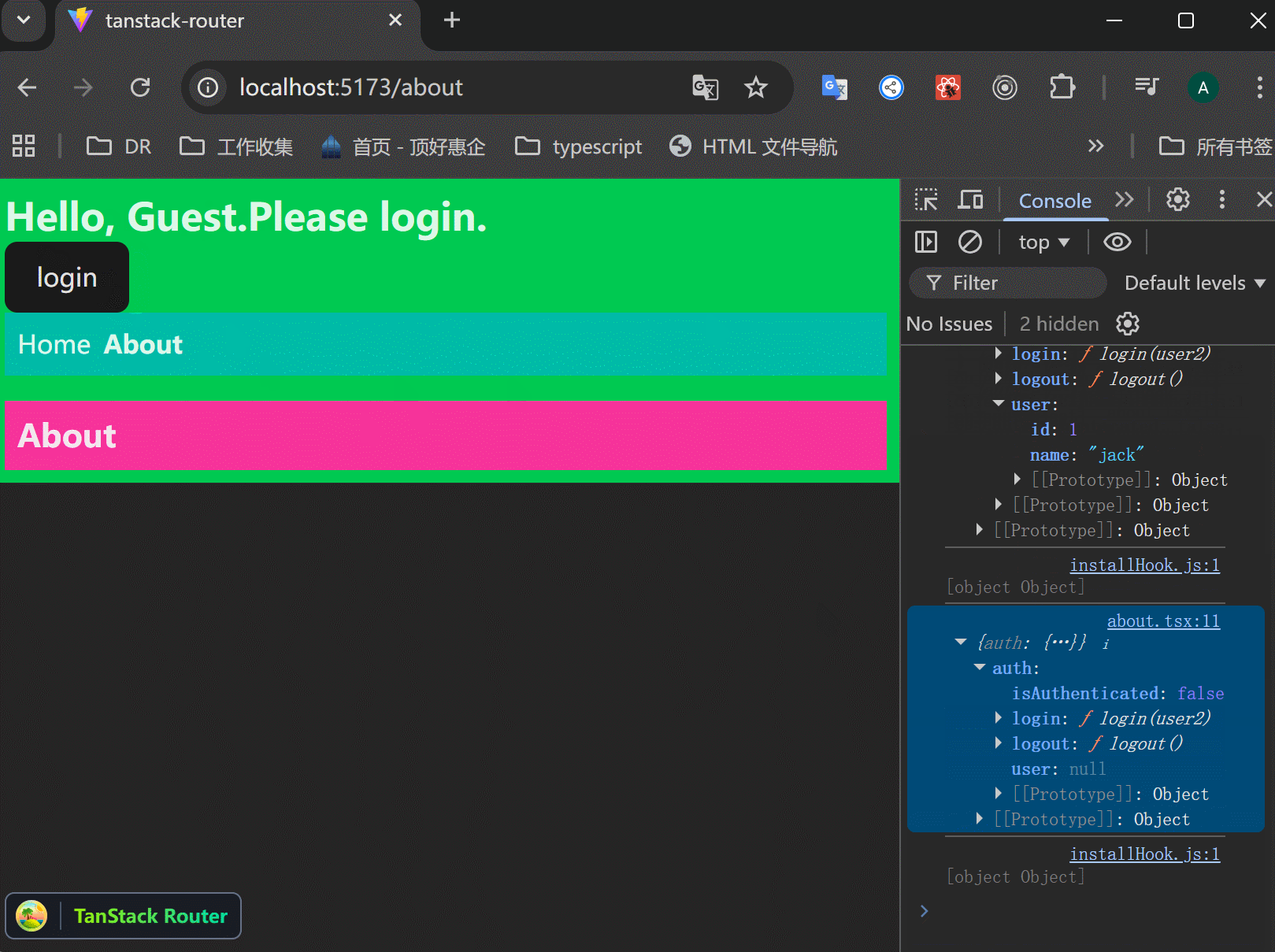
Loader Functions: Posts Page
在 TanStack Router 中,Load(加载) 是其最核心的机制。它遵循“并行加载”和“渲染前获取数据”的原则,彻底解决了传统 React 应用中常见的“瀑布流(Waterfall)”加载问题。
以下是与 Load 相关的核心方法及其应用场景:
1. beforeLoad:准入与前置逻辑
这是路由解析流程中的第一个钩子。它在 loader 运行之前执行,主要用于鉴权、重定向或向 Context 注入数据。
- 特性:如果它抛出错误或重定向,
loader永远不会执行。 - 常见用途:检查用户是否登录。
xxxxxxxxxx91export const Route = createFileRoute('/admin')({2 beforeLoad: ({ search, context }) => {3 if (!context.auth.isAuthenticated) {4 throw redirect({ to: '/login' })5 }6 // 返回的内容会被合并到该路由及其子路由的 context 中7 return { adminToken: 'secret-123' } 8 },9})2. loader:获取数据的主战场
这是最常用的方法。它在路由匹配时异步执行,返回的数据可以通过 Route.useLoaderData() 在组件中访问。
- 核心优势:它是并行的。如果你进入
/users/1/posts,users的 loader 和posts的 loader 会同时启动,而不是等待。 - 自动依赖:当
params或search变化时,loader会自动重新运行。
xxxxxxxxxx61export const Route = createFileRoute('/users/$userId')({2 // 这里的参数都是强类型的3 loader: async ({ params: { userId }, context }) => {4 return await fetchUserById(userId, context.adminToken)5 },6})3. staleTime & gcTime:加载缓存控制
TanStack Router 内置了轻量级的缓存机制(虽然它也经常配合 TanStack Query 使用)。
staleTime:数据被认为是“新鲜”的时长(毫秒)。在此时间内再次访问路由,不会重新触发loader。preloadStaleTime:预加载数据的有效期。
xxxxxxxxxx41export const Route = createFileRoute('/products')({2 loader: () => fetchProducts(),3 staleTime: 1000 * 60 * 5, // 5分钟内不重新加载数据4})4. shouldReload:精细化重新加载
默认情况下,任何 URL 参数变化都会触发 loader。shouldReload 允许你自定义什么时候需要重新加载数据。
xxxxxxxxxx61export const Route = createFileRoute('/search')({2 shouldReload: ({ search, nextSearch }) => {3 // 只有当搜索关键词改变时才重新加载,忽略分页改变4 return search.q !== nextSearch.q 5 },6})5. pendingComponent & pendingMs:加载状态
这是提升用户体验的神器。当 loader 运行时间超过设定值时,会自动渲染该组件。
pendingMs:延迟显示的毫秒数(防止网络很快时 loading 闪烁)。
xxxxxxxxxx51export const Route = createFileRoute('/heavy-page')({2 loader: () => fetchHugeData(),3 pendingMs: 500, // 超过 500ms 才显示 Loading4 pendingComponent: () => <Skeleton />,5})总结:Load 相关方法的执行顺序
beforeLoad:检查权限,准备 Context。loader:并行异步请求数据。pendingComponent:如果 loader 太慢,中间插播 Loading 界面。component:数据准备就绪,正式渲染。errorComponent:如果上述任何环节出错,跳转到这里。
进阶:如何获取正在加载的状态?
如果你想在全局(比如顶部进度条)显示加载状态,可以使用 useRouterState。
xxxxxxxxxx41function GlobalSpinner() {2 const isLoading = useRouterState({ select: (s) => s.status === 'pending' })3 return isLoading ? <Spinner /> : null4}老师的案例
创建一个posts页面,然后获取列表数据:
xxxxxxxxxx411// src/routes/posts/index.tsx23import { createFileRoute, Link } from "@tanstack/react-router";4import { getPosts, type Post } from "../../data/posts";56export const Route = createFileRoute("/posts/")({7 component: RouteComponent,8 beforeLoad: () => {9 return {10 getPosts,11 };12 },13 loader: async ({ context }) => {14 const { getPosts } = context;15 const posts = await getPosts();16 return {17 posts: posts.posts,18 };19 },20});2122function RouteComponent() {23 const { posts } = Route.useLoaderData() as {24 posts: Post[];25 };26 return (27 <>28 <div>Hello "/posts/"!</div>29 {posts.map((post) => (30 <div key={post.id}>31 <Link32 to={`/posts/$postId`}33 params={{ postId: String(post.id) }}34 className="underline font-bold text-lg">35 {post.title}36 </Link>37 </div>38 ))}39 </>40 );41}xxxxxxxxxx111// src/routes/posts/$postId.tsx23import { createFileRoute } from "@tanstack/react-router";45export const Route = createFileRoute("/posts/$postId")({6 component: RouteComponent,7});89function RouteComponent() {10 return <div>Hello "/posts/$postId"!</div>;11}可以看到,跳转到posts页面之后,就成功渲染了列表,并且跳转详情成功:
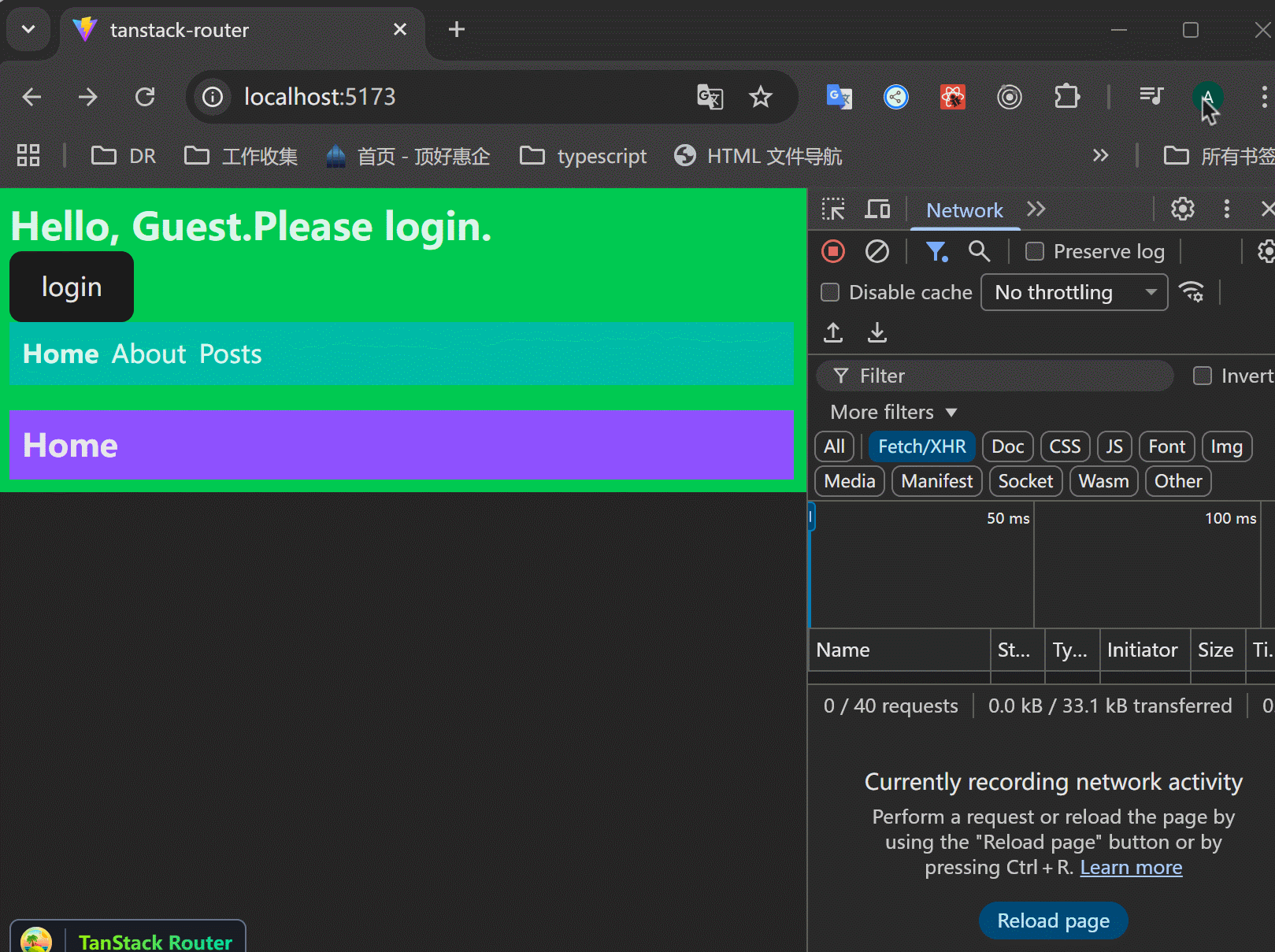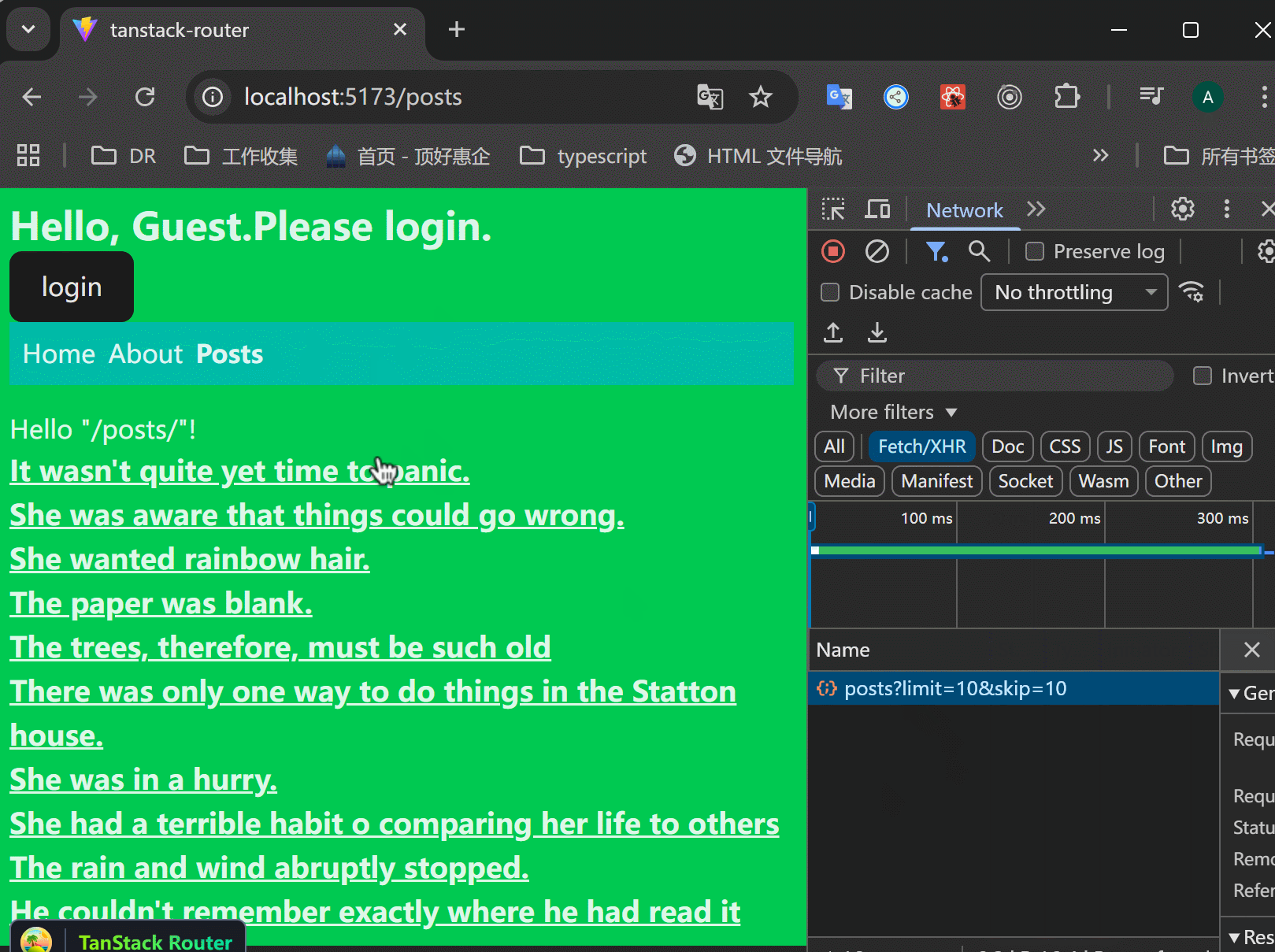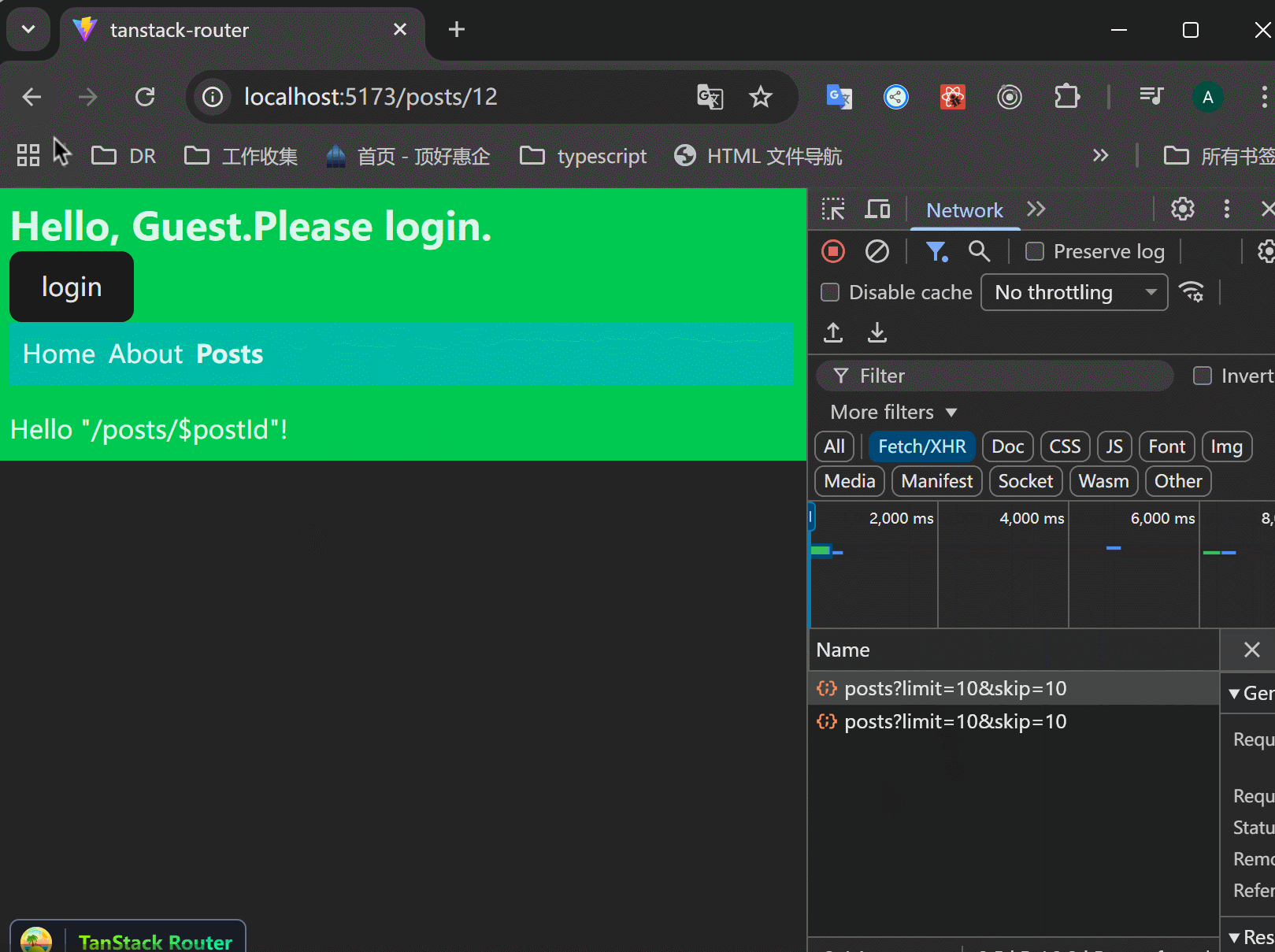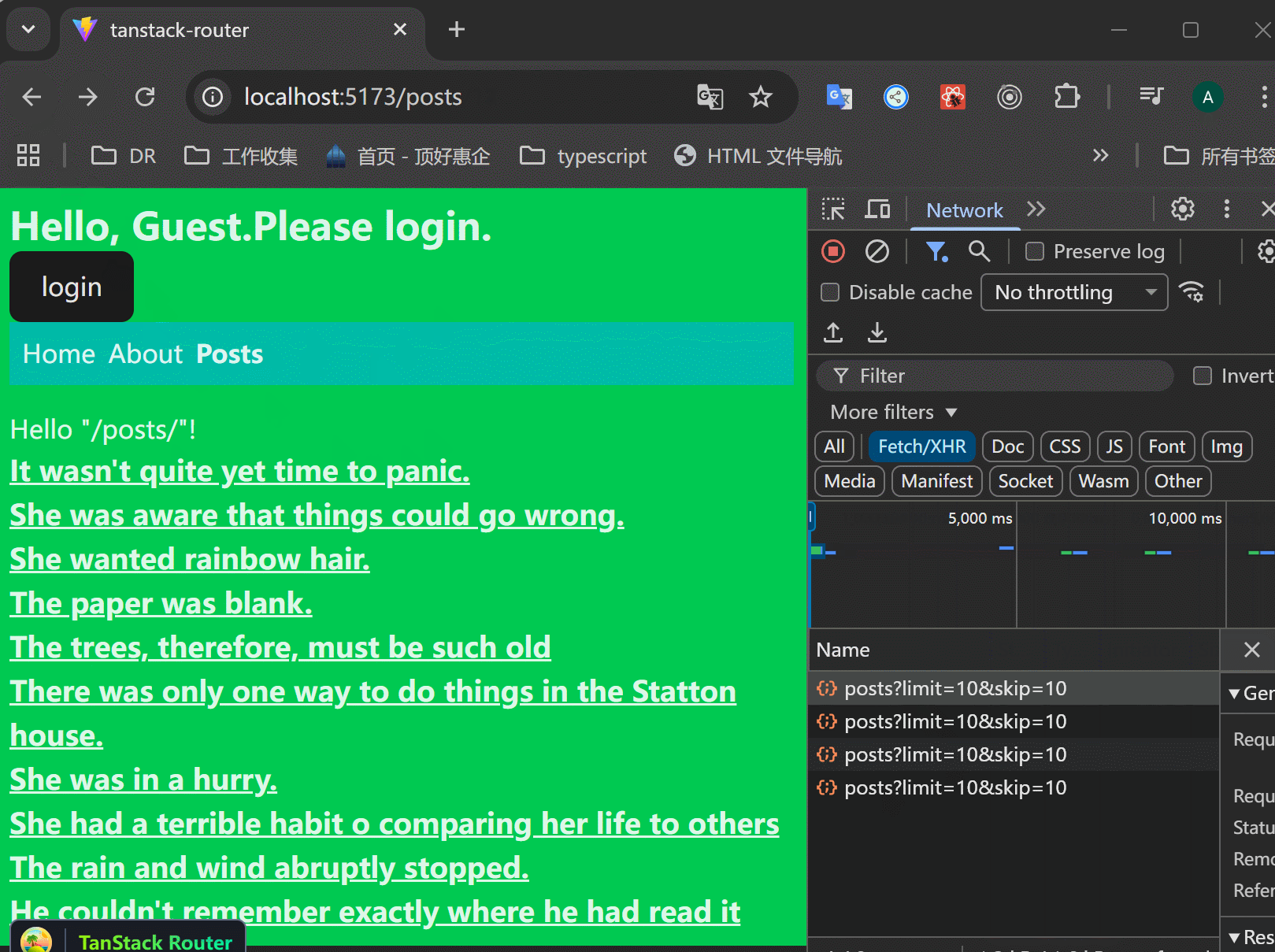
我有一个问题:
在preload和loader里面,都可以获取数据,为什么老师要在preload里面暴露一个fetch接口给loader里面使用呢?有什么好处吗?
这种写法是 TanStack Router 中非常高级且推荐的依赖注入(Dependency Injection)模式。你通过
beforeLoad将一个函数(getPosts)注入到 Context 中,然后在loader里消费它。这样做主要有以下四个核心好处:
1. 实现“逻辑与路由”的解耦
这种写法允许你在路由定义之外准备好业务逻辑。
- 好处:你的路由配置不再直接依赖于具体的 API 实现。
- 场景:如果以后
getPosts的来源从 REST API 换成了 GraphQL 或者本地缓存,你只需要修改注入的地方,而不需要动每个路由的loader代码。2. 极大地简化单元测试(Easy Mocking)
这是这种模式最大的优势。
- 痛点:如果
loader直接 import 了api.ts,测试时很难拦截这个请求。- 解法:在测试环境中,你可以在创建 Router 时,通过 Context 注入一个 Mock 版的
getPosts。- 效果:你的
loader变成了纯粹的逻辑测试,不需要处理复杂的网络请求模拟。3. 统一处理副作用或配置
通过 Context 注入的方法,通常已经预设好了必要的参数。
- 好处:例如
getPosts在注入前可能已经绑定好了当前的basePath、headers或auth token。- 代码观感:
loader内部变得非常干净,它只需要知道“我需要调用这个函数拿数据”,而不需要知道“如何构建请求”。4. 解决循环依赖问题
在大型 React 项目中,API 文件夹、组件文件夹和路由文件夹之间经常发生循环引用(Circular Dependency)。
- 原理:通过
beforeLoad返回对象来扩展 Context,实际上是将依赖的控制权交给了上一级或外部。- 结果:这被称为“控制反转(IoC)”,是解决大型复杂前端项目架构问题的常用手段。
对比一下普通写法:
普通写法(直接调用):
xxxxxxxxxx41loader: async () => {2const posts = await fetchPostsFromApi(); // 强耦合,测试难,配置散乱3return { posts };4}你的图片中的写法(依赖注入):
xxxxxxxxxx51beforeLoad: () => ({ getPosts }), // 注入能力2loader: async ({ context }) => {3const data = await context.getPosts(); // 消费能力,高内聚低耦合4return { posts: data.posts };5}
Adding Pagination
这节课学习为列表添加分页功能。
在 TanStack Router 中,loader 默认只在路径参数(params)改变时触发。如果你想让 loader 在 URL 的 Search Params(查询参数) 改变时也重新运行,你就必须使用 loaderDeps。
1. 什么是 loaderDeps?
loaderDeps 是一个函数,它告诉 Router:“除了路径变化外,我还依赖哪些额外的参数”。如果这个函数返回的值发生了变化,Router 就会重新执行 loader。
它通常配合 validateSearch 使用。
2. 代码示例:处理分页
假设你要根据 URL 里的 page 参数来拉取数据:
xxxxxxxxxx171export const Route = createFileRoute("/posts/")({2 // 1. 先校验并定义 Search 参数的形状3 validateSearch: (search) => ({4 page: (search.page as number) || 1,5 }),67 // 2. 关键:将 search 参数映射到依赖中8 // 只有这里返回的对象变了,loader 才会重新跑9 loaderDeps: ({ search: { page } }) => ({ page }),1011 // 3. 现在 loader 可以拿到这个 page 并请求数据了12 loader: async ({ context, deps: { page } }) => {13 const { getPosts } = context;14 // 调用你之前定义的 getPosts,传入正确的页码15 return await getPosts(page); 16 },17});3. 为什么必须用 loaderDeps?
如果没有 loaderDeps,会发生以下情况:
- 用户从
/posts?page=1点击跳转到/posts?page=2。 - 因为 路径 依然是
/posts/没变,Router 为了性能优化,默认不会重新触发loader。 - 你的界面会停留在第一页的数据,URL 变了但内容没变。
加上 loaderDeps 后,Router 会对比旧的 deps 和新的 deps。一旦发现 page 从 1 变成了 2,它就会立即触发加载逻辑。
4. loaderDeps 的工作流程
- 用户操作:点击了带有新
search参数的<Link>。 - 校验:
validateSearch确保参数合法。 - 依赖检查:Router 执行
loaderDeps,对比返回的依赖对象。 - 重新加载:如果依赖项不同,触发
loader。 - 数据流向:
loader拿到新的deps,请求 API,最后通过useLoaderData传给组件。
5. 常见坑点:不要把整个 search 传进去
在 loaderDeps 中,建议只返回你真正依赖的字段,而不是返回整个 search 对象。
- 错误做法:
loaderDeps: ({ search }) => search。如果 URL 里多了一个不相关的参数(比如?tab=info),loader也会被无意义地重新触发。 - 正确做法:只提取需要的字段,如
({ search: { page, filter } }) => ({ page, filter })。
总结
params:路径参数改变时,loader自动重跑(不需要loaderDeps)。search:查询参数改变时,loader不会自动重跑,必须通过loaderDeps显式声明依赖。
老师案例
xxxxxxxxxx651// src/routes/posts/index.tsx23import { createFileRoute, Link } from "@tanstack/react-router";4import { getPosts, type Post } from "../../data/posts";5import z from "zod";6import { zodValidator } from "@tanstack/zod-adapter";78const postsSearchParamsSchema = z.object({9 page: z.number().optional(),10});1112export const Route = createFileRoute("/posts/")({13 component: RouteComponent,14 validateSearch: zodValidator(postsSearchParamsSchema),15 beforeLoad: () => {16 return {17 getPosts,18 };19 },20 loaderDeps: ({ search: { page } }) => ({ page }),21 loader: async ({ context, deps: { page } }) => {22 const { getPosts } = context;23 const posts = await getPosts(page);24 return {25 posts: posts.posts,26 count: posts.total,27 };28 },29});3031function RouteComponent() {32 const { posts, count } = Route.useLoaderData();33 return (34 <>35 <div>Hello "/posts/"!</div>36 {posts.map((post) => (37 <div key={post.id}>38 <Link39 to={`/posts/$postId`}40 params={{ postId: String(post.id) }}41 className="underline font-bold text-lg">42 {post.id} - {post.title}43 </Link>44 </div>45 ))}46 <div className="w-80 flex justify-between items-center mt-2">47 <Link48 from={Route.fullPath}49 search={(prev) => ({50 page: (prev.page || 1) - 1,51 })}>52 <button>Prev Page</button>53 </Link>54 <span>total: {count}</span>55 <Link56 from={Route.fullPath}57 search={(prev) => ({58 page: (prev.page || 1) + 1,59 })}>60 <button>Next Page</button>61 </Link>62 </div>63 </>64 );65}
可以看到,翻页非常顺畅。
Loading Data in Parallel: Single Blog Post Page
这节课学习平行请求。在post详情页面,同时获取post详情和相应的评论数据。
通常的做法
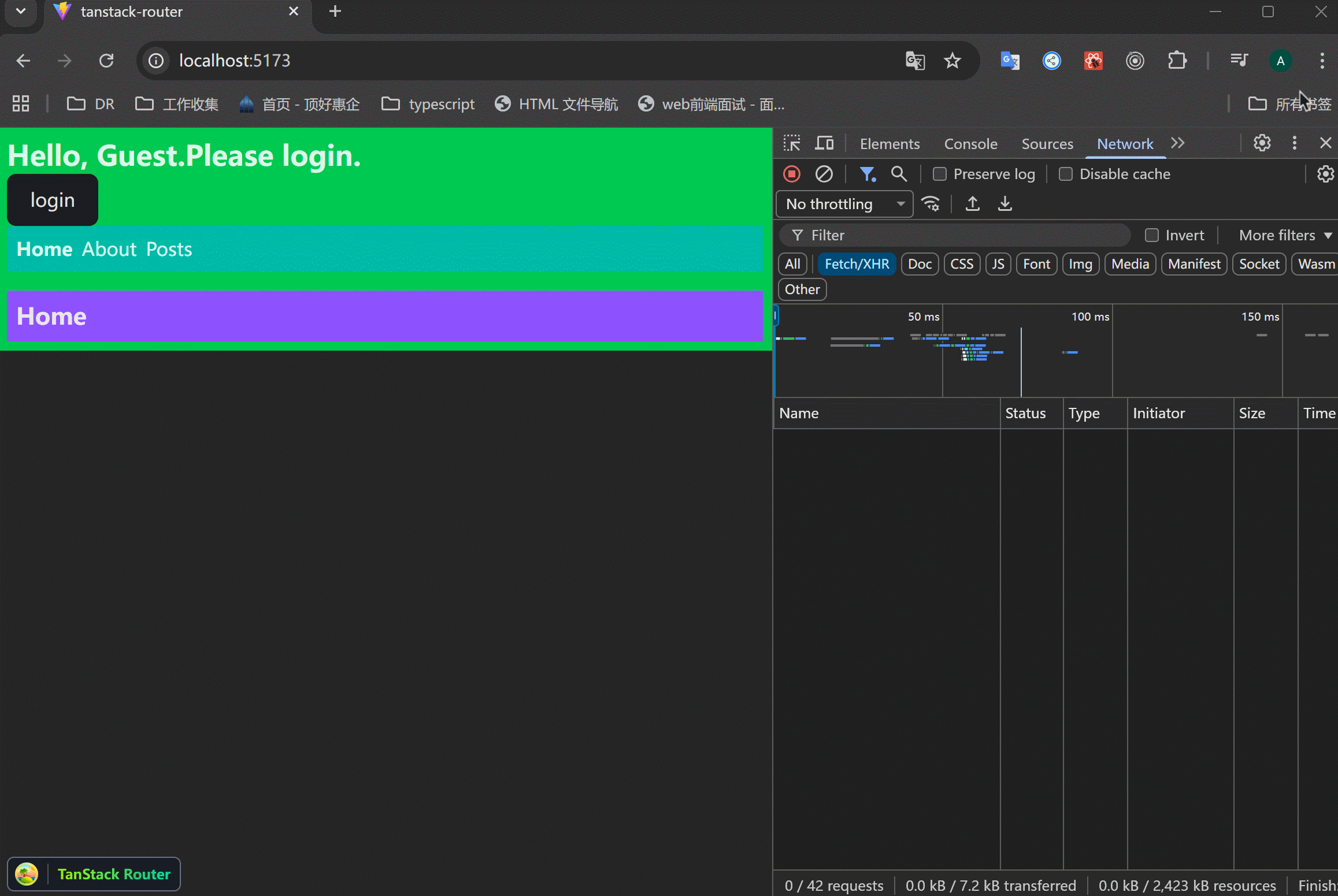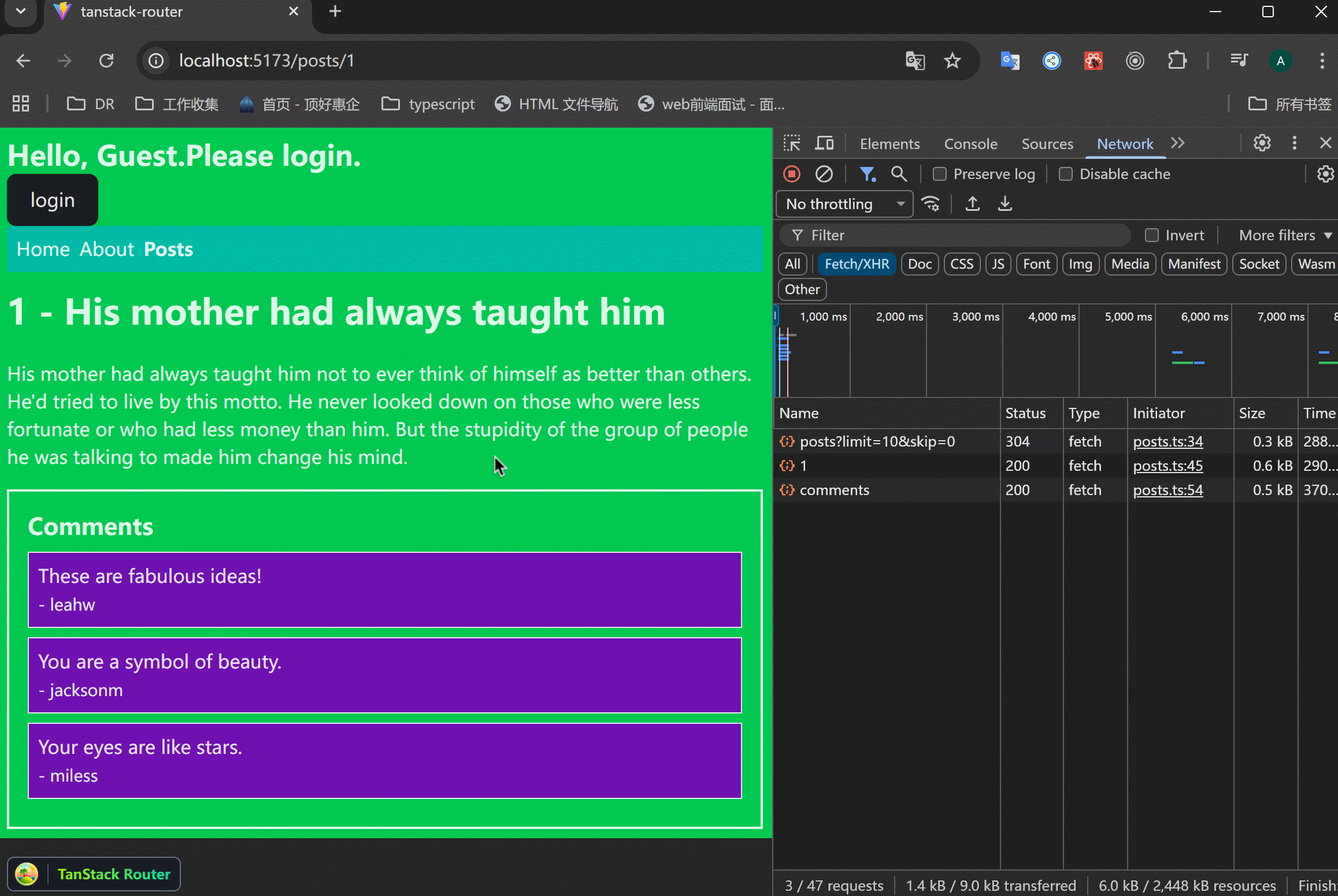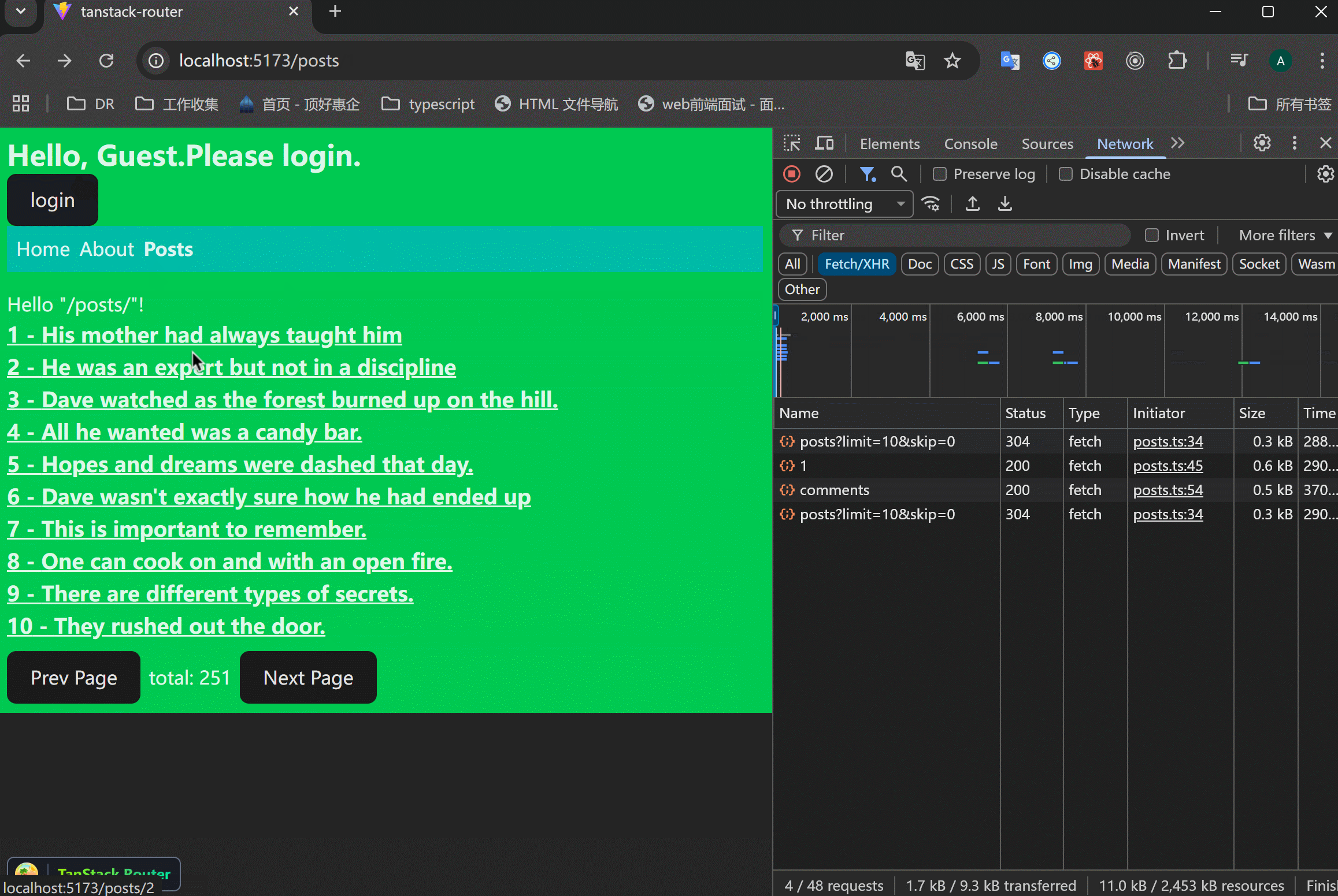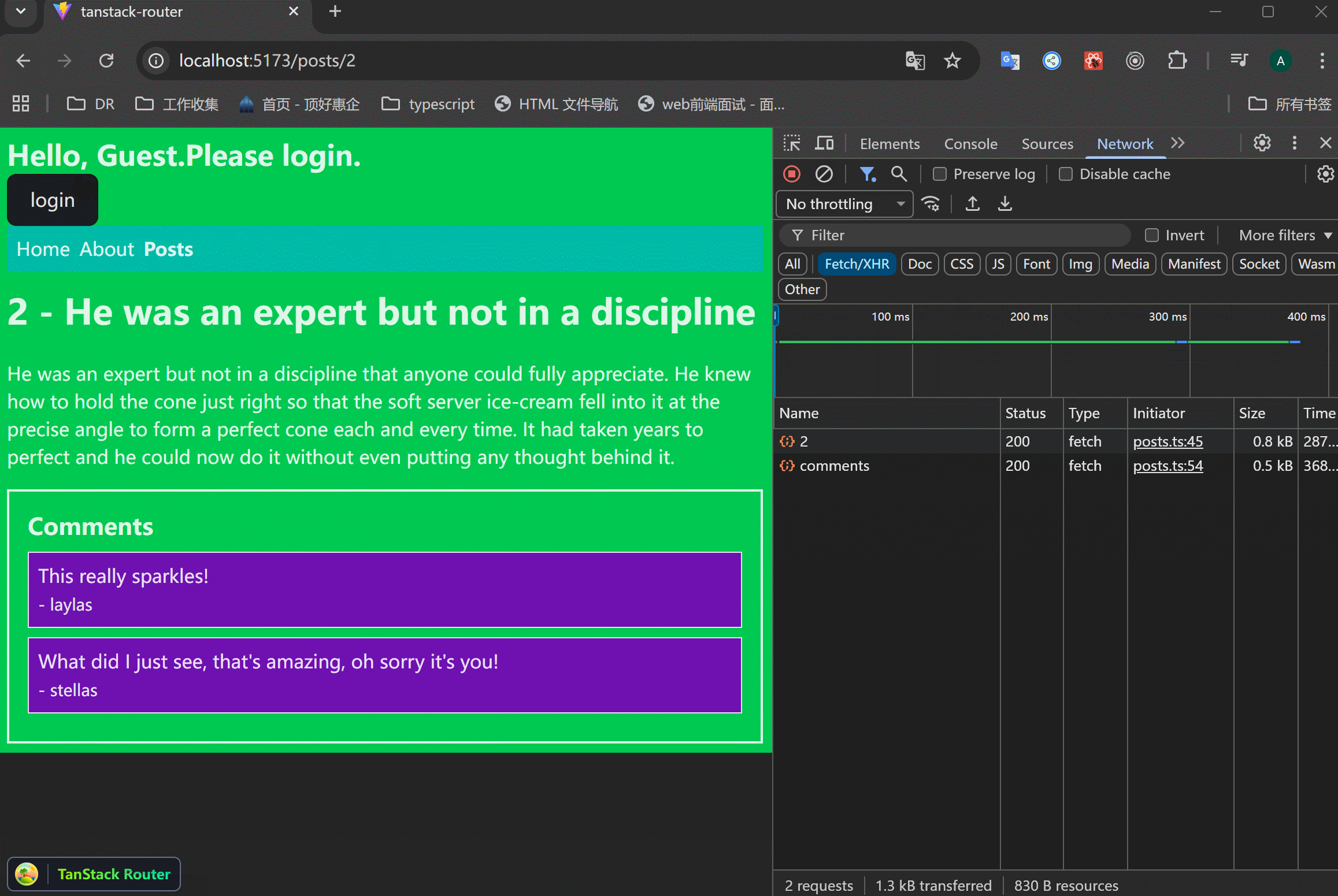
xxxxxxxxxx201// src/routes/posts/$postId.tsx23import { createFileRoute } from "@tanstack/react-router";4import { getPost, getPostComments } from "../../data/posts";56export const Route = createFileRoute("/posts/$postId")({7 component: RouteComponent,8 loader: async ({ params }) => {9 const post = await getPost(+params.postId);10 const comments = await getPostComments(+params.postId);11 return {12 post,13 comments,14 };15 },16});1718function RouteComponent() {19 return <div>Hello "/posts/$postId"!</div>;20}这样的结果是:一个接口请求了之后,才会执行下一个请求。注意看右边的Network执行情况。
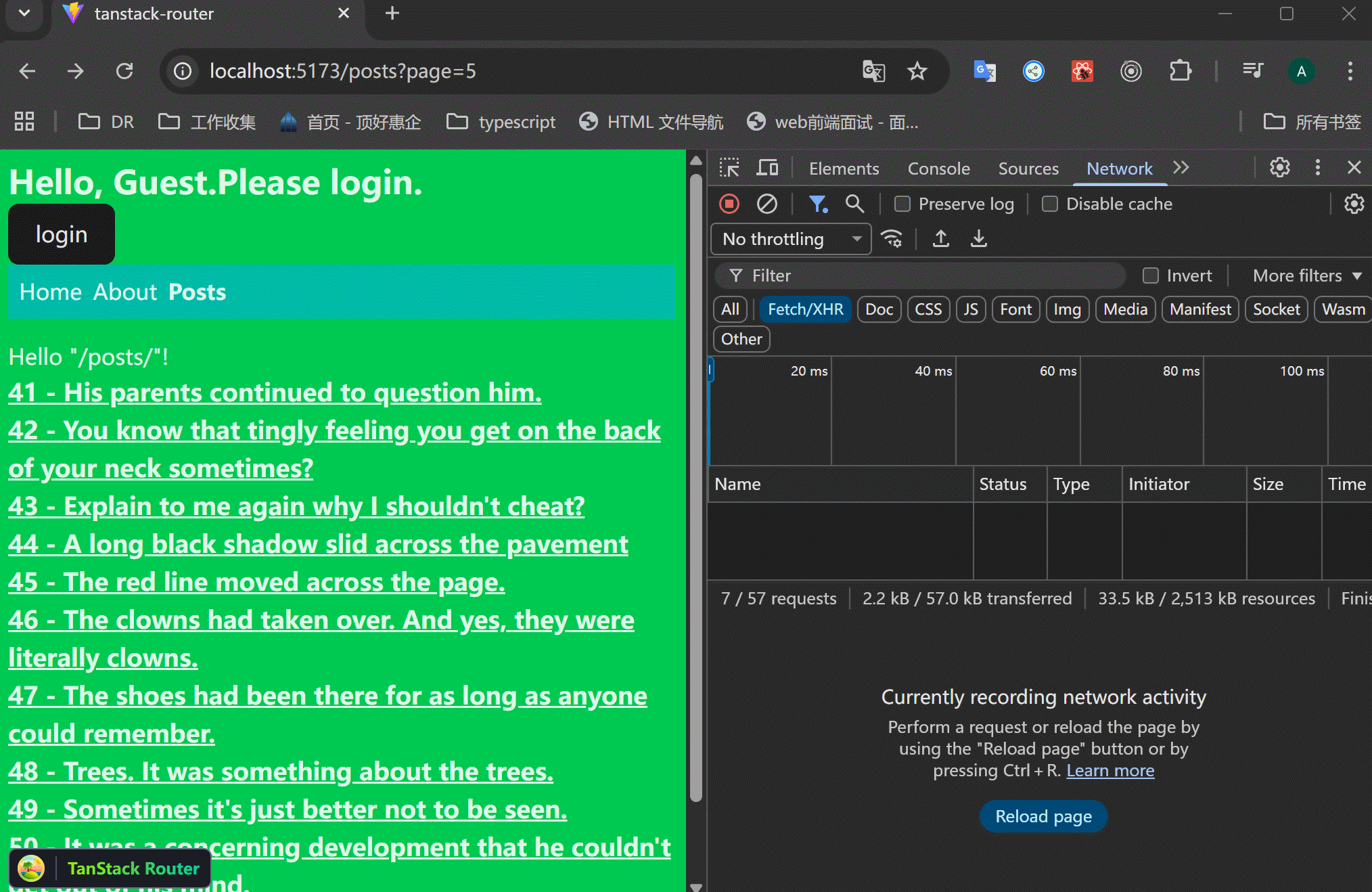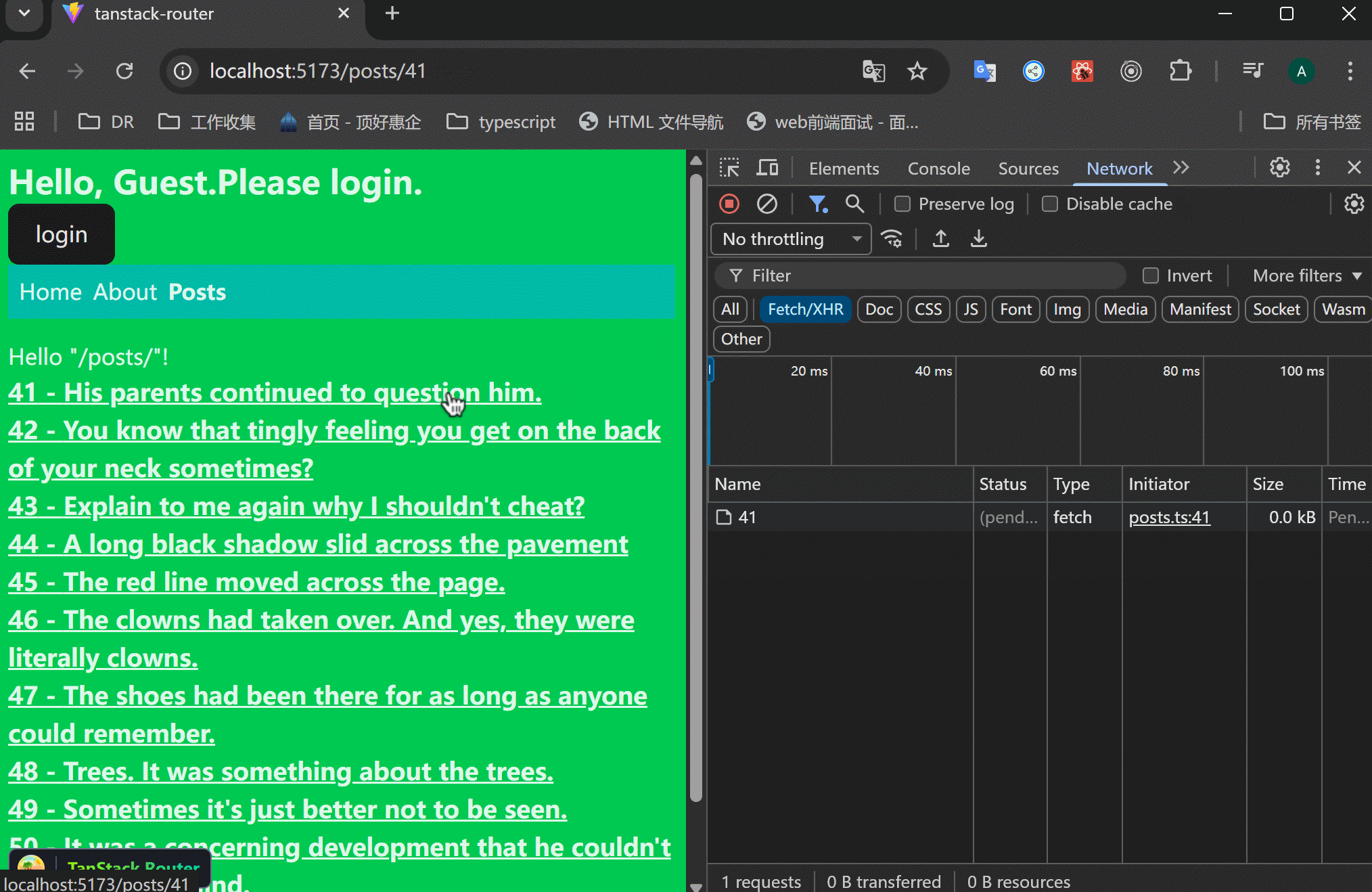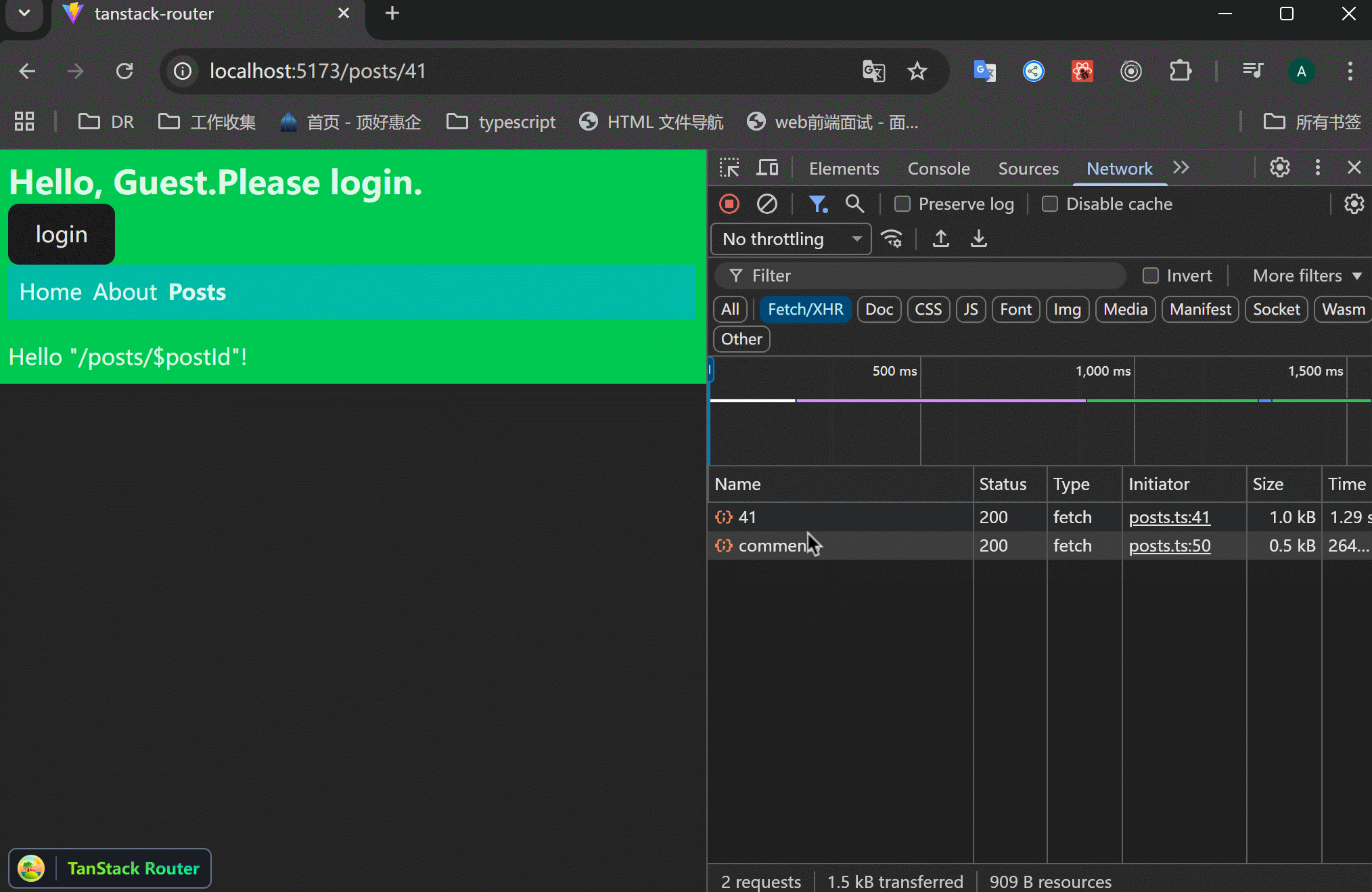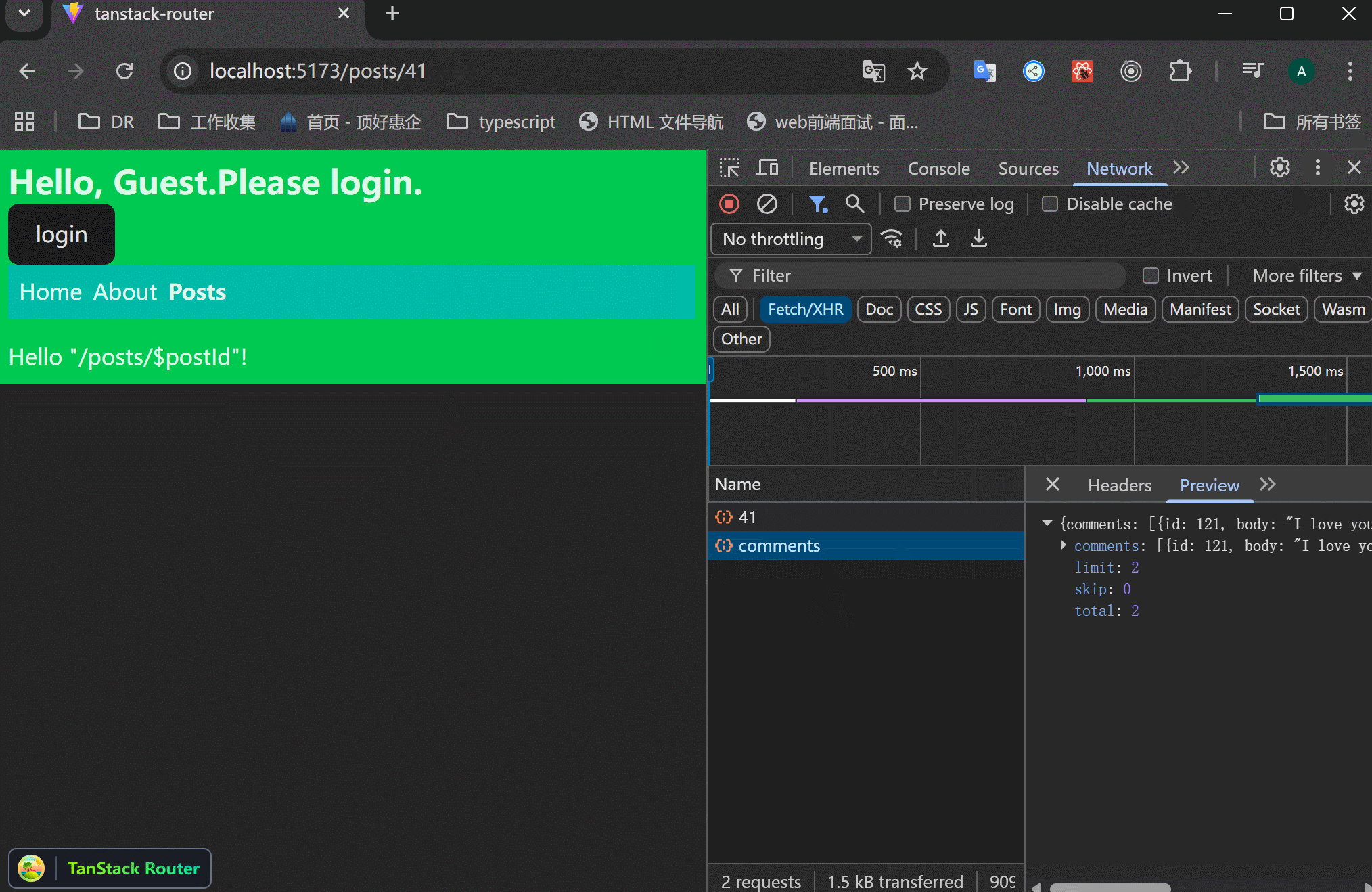
平行请求
使用Promise.all来做平行请求。
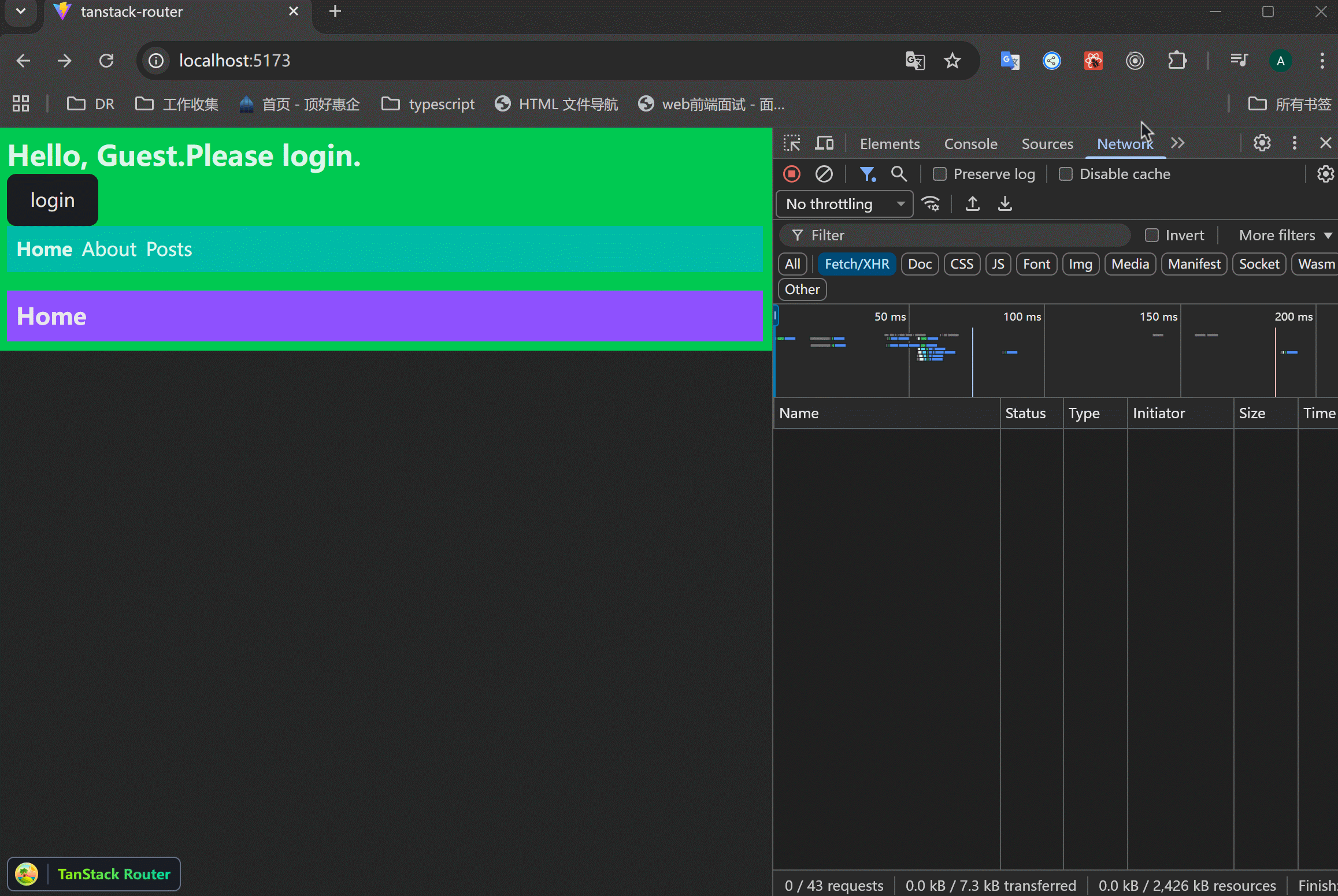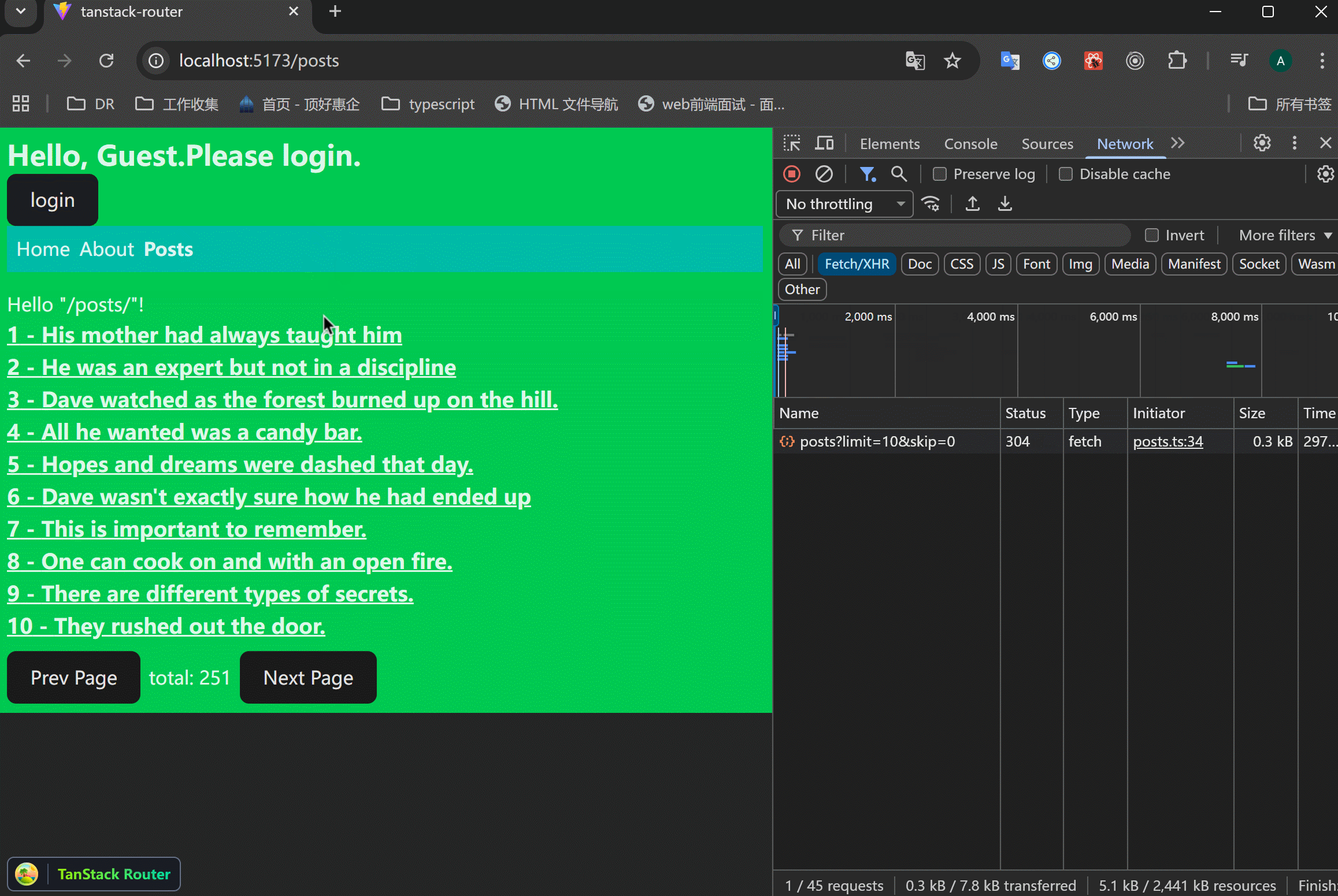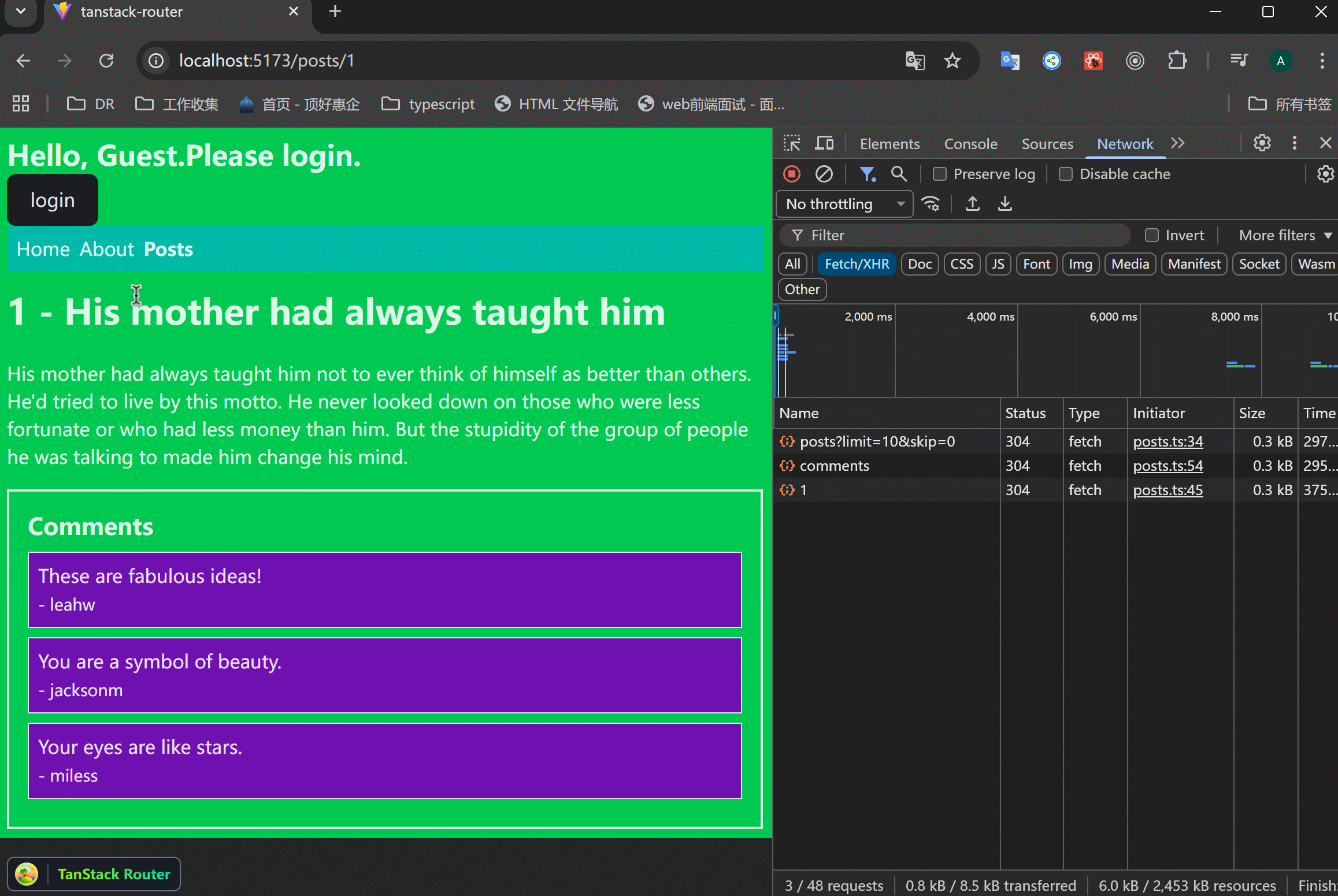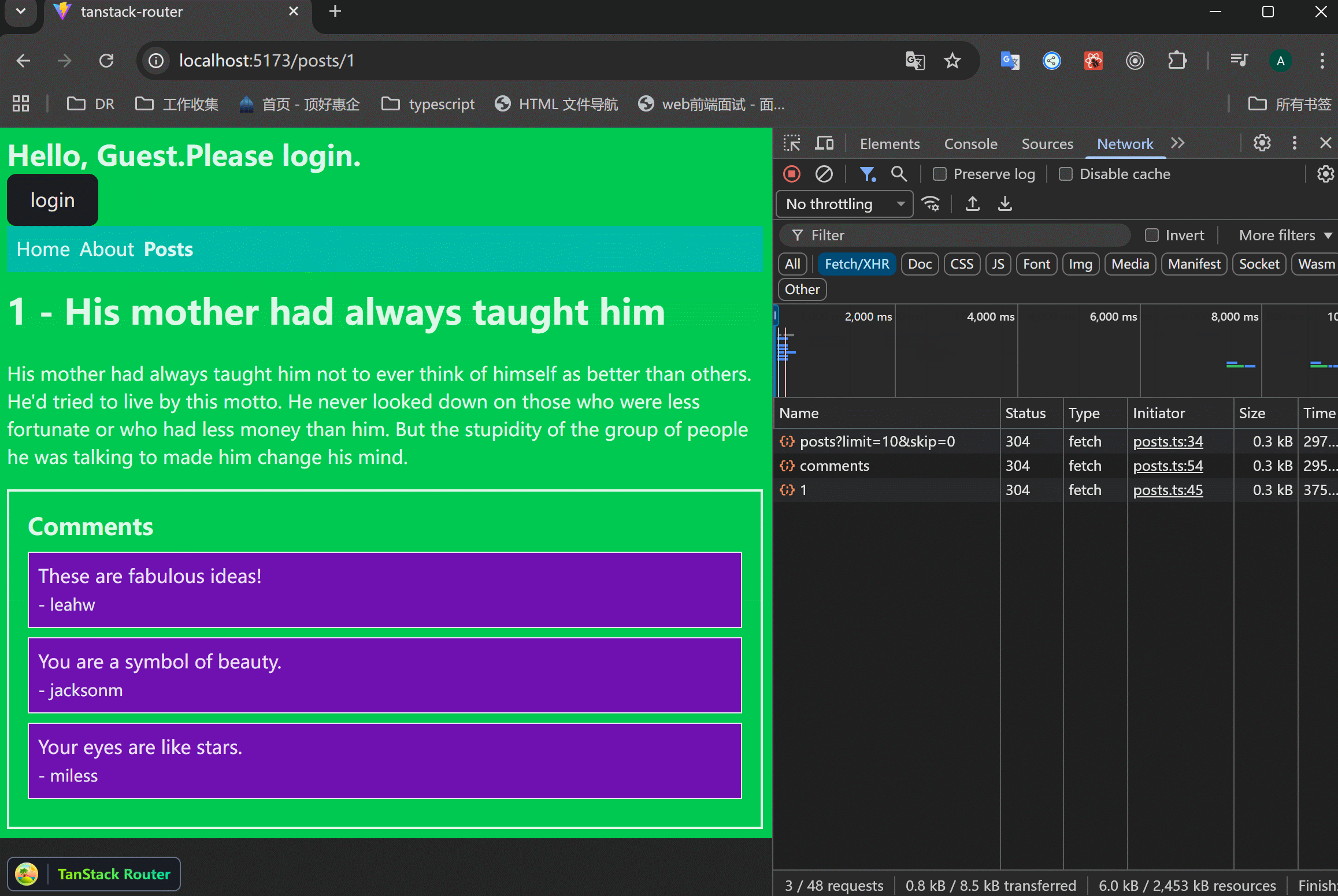
xxxxxxxxxx471// src/routes/posts/$postId.tsx23import { createFileRoute } from "@tanstack/react-router";4import { getPost, getPostComments } from "../../data/posts";56export const Route = createFileRoute("/posts/$postId")({7 component: RouteComponent,8 loader: async ({ params }) => {9 const [post, comments] = await Promise.all([10 getPost(+params.postId),11 getPostComments(+params.postId),12 ]);1314 return {15 post,16 comments,17 };18 },19});2021function RouteComponent() {22 const { postId } = Route.useParams();23 const { post, comments } = Route.useLoaderData();24 return (25 <div>26 <h1 className="text-3xl font-bold mb-6">27 {postId} - {post.title}28 </h1>29 <p>{post.body}</p>30 <div>31 <h2>Comments</h2>32 <ul>33 {comments.comments.map((comment) => (34 <li key={comment.id} className="bg-purple-800 border p-2 mb-2">35 {comment.body}36 <br />37 <span className="text-sm text-gray-200">38 {" "}39 - {comment.user.username}40 </span>41 </li>42 ))}43 </ul>44 </div>45 </div>46 );47}可以看到,两个请求是同时发起的,节约了时间。
Pending State Component
假设接口返回很慢,这时候页面就会有明显的卡顿。parallel请求里面,只要有一个请求慢,那么整个页面都会受到影响。
可以看到,从列表页面进入的时候,只有接口返回了,才会显示详情页面。并且刷新详情页面的时候,只有接口返回了,才会显示页面,有空白页面的情况。
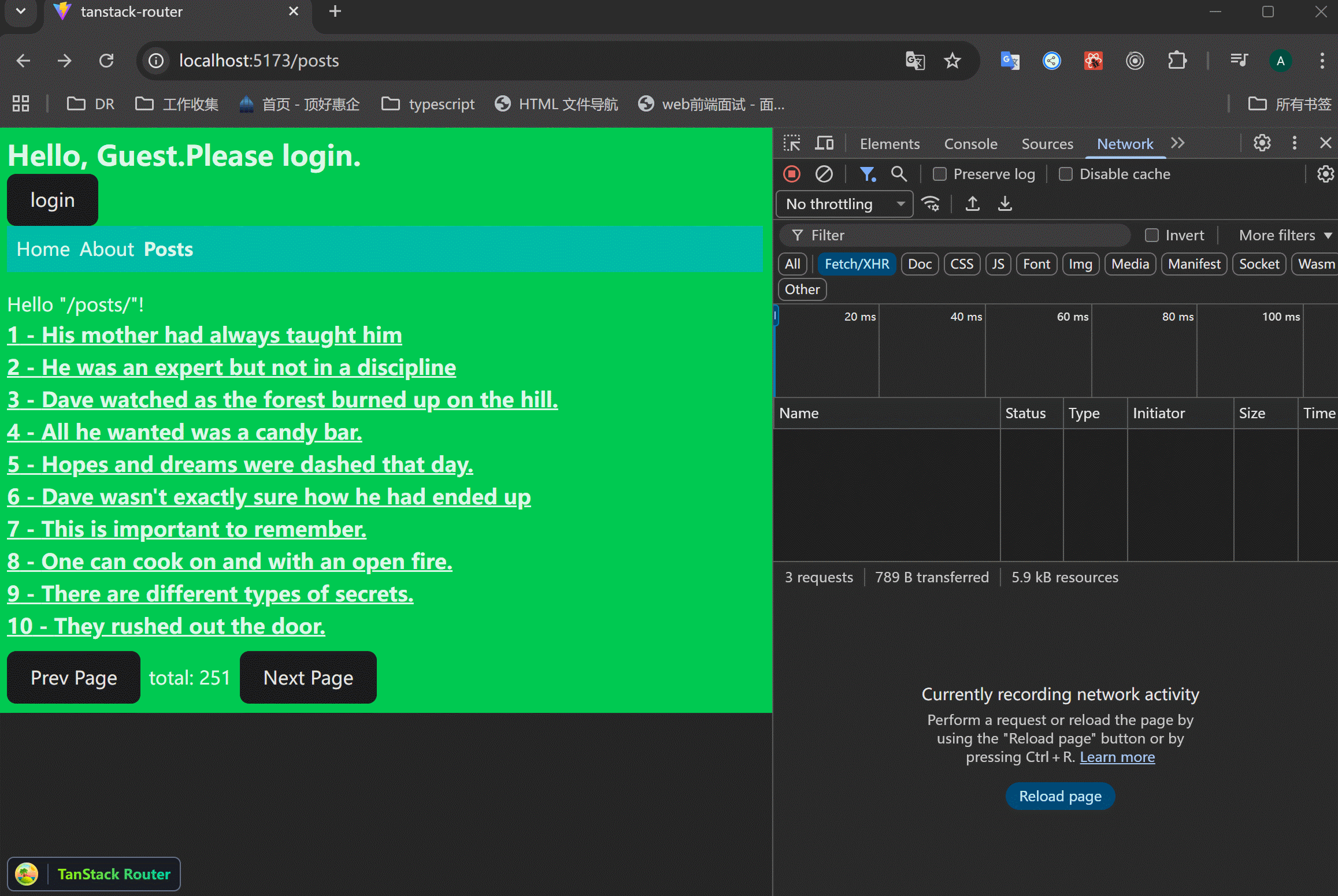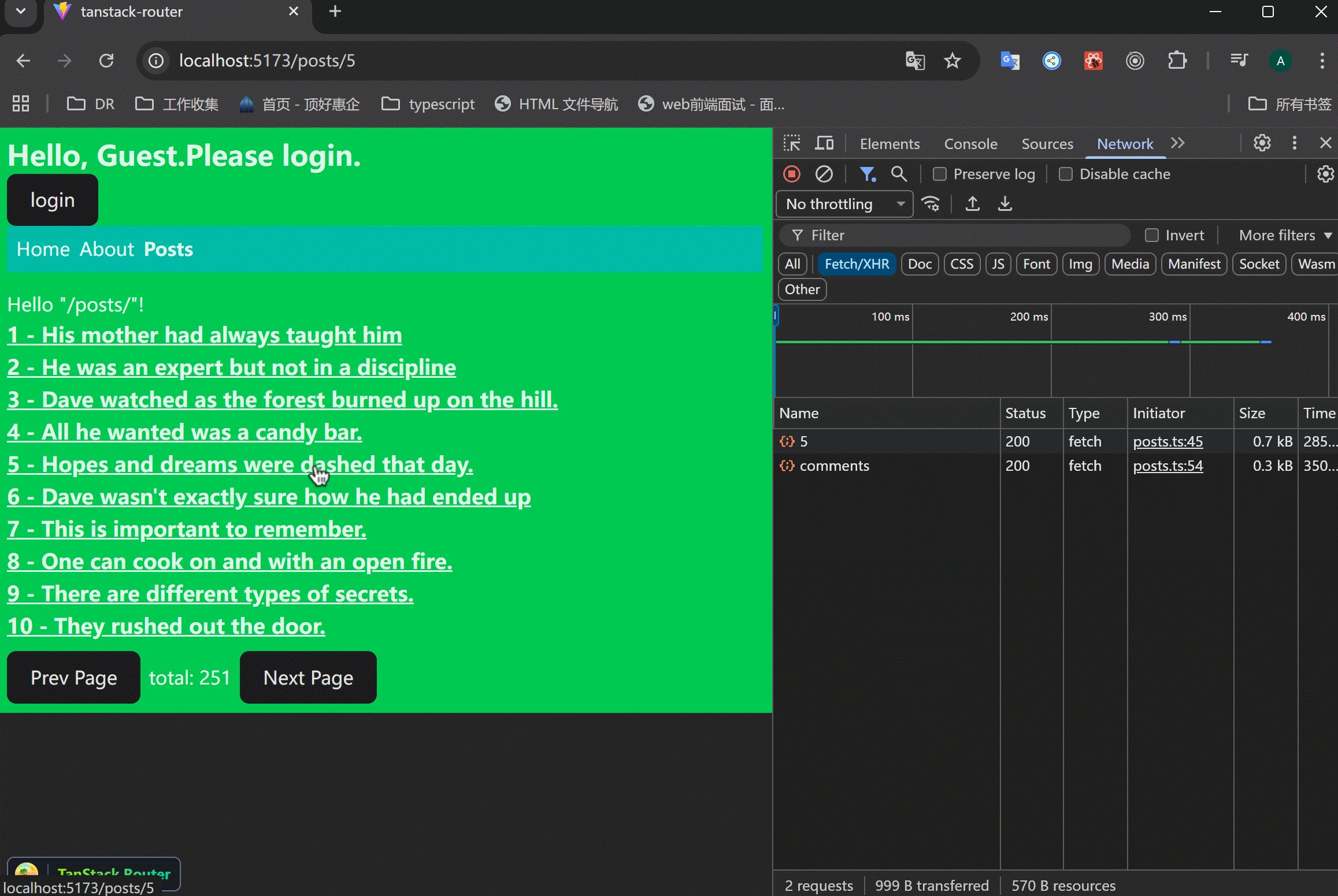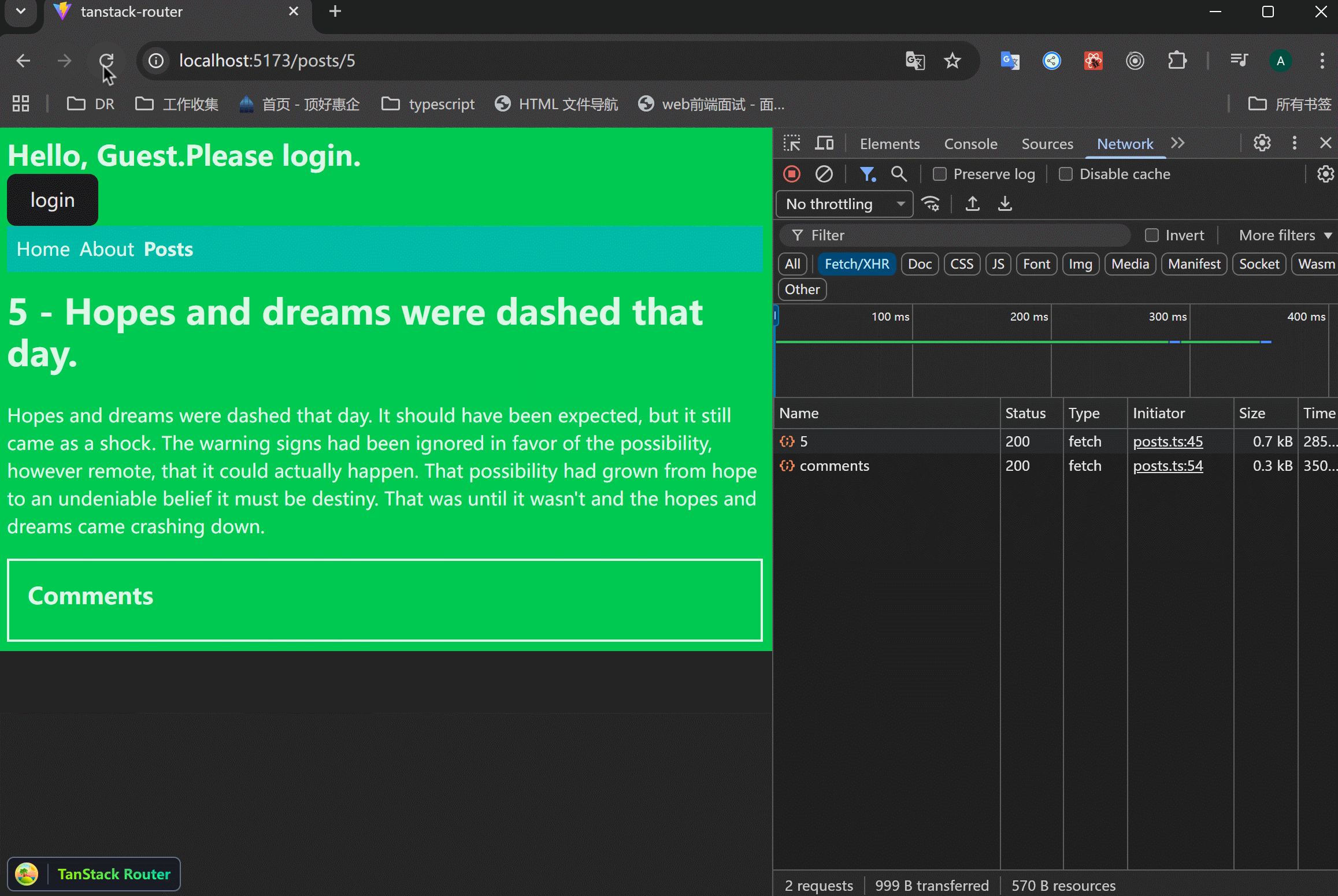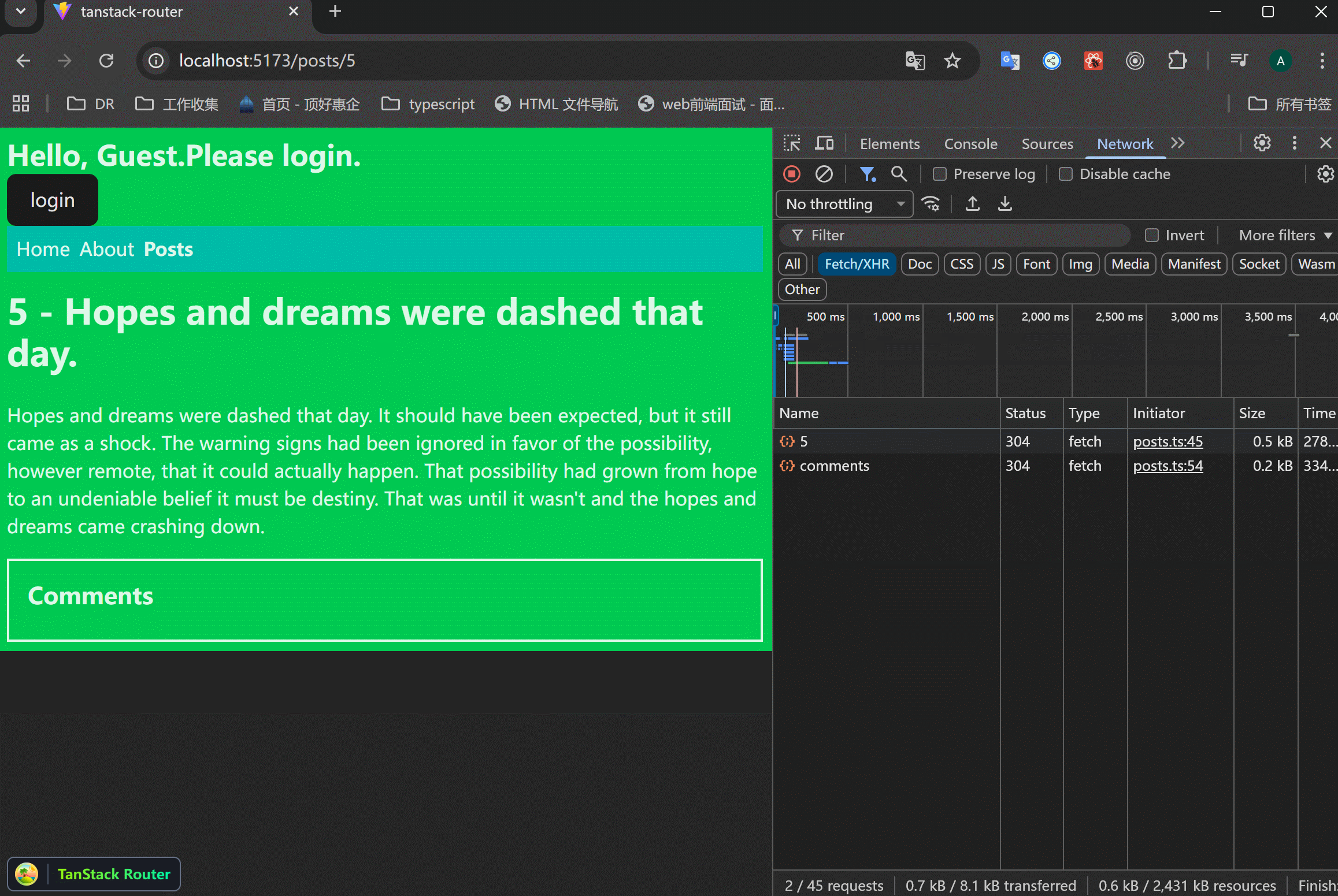
需要设置pending state相关的属性来解决上面的问题。
相关属性
如何既能提示用户正在加载,又能避免 Loading 界面一闪而过的“闪烁”感?
1. pendingComponent
这是你要展示的 Loading 界面 本身。
- 功能:当
loader正在抓取数据且耗时超过了pendingMs时,Router 会渲染这个组件代替原来的component。 - 内容:通常是一个转圈圈的 Spinner、骨架屏(Skeleton)或简单的 "Loading..." 文字。
2. pendingMs
这是 “等待多久才显示 Loading” 的延迟时间。
- 功能:如果你的 API 请求非常快(比如 50ms 就回来了),用户其实不需要看到 Loading 界面。
- 你的配置 (
0):意味着立即显示。只要开始加载,立马跳出pendingComponent。 - 推荐值:通常设为
200到500之间。这样只有在网络慢的时候用户才会看到加载中,网络快时用户感觉不到切换。
3. pendingMinMs
这是 “Loading 界面最少显示多久”。
- 功能:防止“Loading 闪烁”。如果 API 在 510ms 回来,而你的
pendingMs是 500ms,Loading 只会出现 10ms 就会消失,用户眼睛会很难受。 - 你的配置 (
500):意味着即便数据在 10ms 内就加载好了,Loading 界面也必须站够 500ms 才能消失。这能让视觉过渡更自然、平滑。
三者结合的逻辑流
精确逻辑流:场景(假设API 耗时 300ms)
0ms - 开始加载:用户点击链接,路由进入
pending状态,浏览器开始计时pendingMs。200ms - 触发显示:此时 API 还没返回(还差 100ms)。因为达到了
pendingMs的阈值,pendingComponent(Loading 界面)正式挂载显示。- 关键点:
pendingMinMs的 500ms 倒计时从这一刻正式开始。
- 关键点:
300ms - 数据返回:API 请求完成,数据已就绪。
- 关键点:此时 Loading 界面仅显示了 100ms。由于未达到
pendingMinMs(500ms)的要求,页面被锁定在 Loading 状态。
- 关键点:此时 Loading 界面仅显示了 100ms。由于未达到
700ms - 结束停留:Loading 界面已经显示了满 500ms(200ms 触发 + 500ms 持续时间)。
正式渲染:切换为正式的
RouteComponent。
结论:在这种情况下,用户从点击到看到页面,总共等待了 700ms。
老师案例
可以看到,loading...效果是过了一段时间(设置的是300ms)才出现的,出现之后就会持续500ms的时间,所以这些数值要根据实际情况来。
全局pending属性
全局 defaultPendingComponent 的默认效果是替换掉整个页面内容。所以这个还是要看需求。
问题:
我发起parallel request请求,如果有一个接口延迟比较久的话,整个页面都会延迟显示,虽然有pending状态可以处理,但是能不能像nextjs里面的parallel routes那样处理呢?
将不同请求作为不同的组件,然后引入到这个route页面里面。然后每个组件里面都有独立的loading状态,互不影响。
TanStack Router 中,如果你想实现类似 Next.js 那种“局部加载、局部占位”的效果,不要在
loader中等待所有的请求。
loader的特性是:它必须执行完毕,页面才会从pending状态转入正式组件。如果你在loader里写了await Promise.all([A, B]),那么 A 和 B 中最慢的那个会拖慢整个页面的首屏显示。要实现并行且独立的局部加载,主要有以下两种方案:
方案一:利用
Suspense与“延迟数据”(最接近 Next.js)TanStack Router 支持在
loader中返回一个不加await的 Promise。这样路由会立即渲染,而数据获取则交给组件内部的Suspense处理。1. 在 Loader 中分发请求
xxxxxxxxxx141export const Route = createFileRoute('/dashboard')({2loader: () => {3// 快速数据:立即 await4const fastData = await fetchFastData()56// 慢速数据:直接返回 Promise,不要 await7const slowDataPromise = fetchSlowData()89return {10fastData,11slowDataPromise, // 传递给组件12}13},14})2. 在组件中局部占位
使用
Await组件(TanStack 提供的工具)来包裹那些慢速请求:xxxxxxxxxx181import { Await } from '@tanstack/react-router'23function RouteComponent() {4const { fastData, slowDataPromise } = Route.useLoaderData()56return (7<div>8<h1>快速显示的内容: {fastData.title}</h1>910{/* 这里的效果就像 Next.js 的 Parallel Routes + Suspense */}11<React.Suspense fallback={<div>加载慢速数据中...</div>}>12<Await promise={slowDataPromise}>13{(data) => <div>慢速数据终于来了: {data.content}</div>}14</Await>15</React.Suspense>16</div>17)18}方案二:组件内独立请求(配合 TanStack Query)
如果你希望不同组件完全独立,互不干扰,甚至不需要在
loader里声明,那么将请求直接移入子组件是最佳选择。
- Loader 只处理关键路径数据(如鉴权、核心 ID)。
- 子组件内部发起请求。
xxxxxxxxxx161function SlowComponent() {2// 使用 TanStack Query 独立获取数据3const { data, isLoading } = useQuery({ queryKey: ['slow'], queryFn: fetchSlowData })45if (isLoading) return <Skeleton />6return <div>{data.content}</div>7}89function RouteComponent() {10return (11<div className="grid grid-cols-2">12<AsideContent /> {/* 快速内容 */}13<SlowComponent /> {/* 独立加载的内容,不会阻塞 AsideContent */}14</div>15)16}
Loading Data in the Background
上节课我就提出了疑问,因为一个接口而让整个页面都显示loading,效果其实也不好,当时有两种解决办法,这里就说第一种解决办法:<Await>组件。
The Await component is a component that suspends until the provided promise is resolved or rejected. This is only necessary for React 18. If you are using React 19, you can use the use() hook instead.
虽然说现在是react 19,可以使用use()来解决了。但是Await组件用起来更加语义化一些,更加好理解。
基本概念
在 TanStack Router 中,<Await> 组件是实现非阻塞式数据加载(Deferred Data)的核心工具。它允许你在 loader 中发起异步请求但不等待其完成,从而让页面框架先渲染,数据则在后台加载完成后局部显示。
1. 为什么需要 <Await>?
在默认情况下,如果你在 loader 里使用 await,Router 必须等数据加载完才会渲染组件。如果接口很慢,用户就会卡在旧页面或看到全局的 pendingComponent。
<Await> 的作用:它接收一个 Promise,并利用 React 的 Suspense 机制,在 Promise 没完成时展示占位图(fallback),完成后自动渲染内容。
2. 核心用法流程
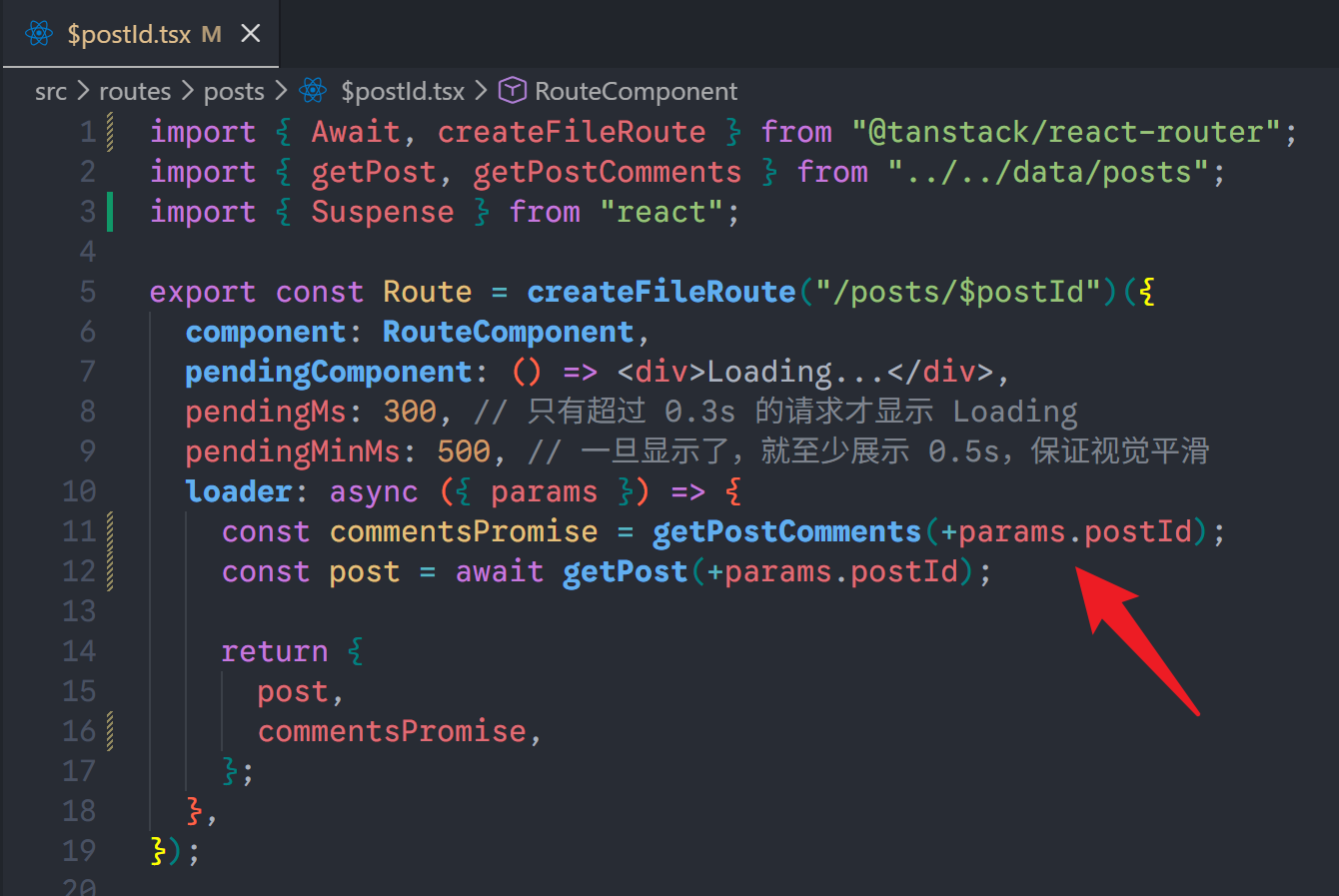
第一步:在 loader 中返回 Promise(不加 await)
不要在慢速请求前写 await,直接将 Promise 对象返回。
xxxxxxxxxx141export const Route = createFileRoute('/posts')({2 loader: () => {3 // 关键:慢请求前面不使用 await,直接发起请求4 const slowDataPromise = getSlowData() 5 6 // 快请求可以使用await7 const fastDataFetch = await getFastData()8 9 return {10 fastDataFetch,11 deferredData: slowDataPromise 12 }13 }14})第二步:在组件中使用 <Await> 包裹
你需要将组件包裹在 Suspense 中,因为 <Await> 会触发“悬停”(suspend)。
xxxxxxxxxx241import { Await } from '@tanstack/react-router'2import { Suspense } from 'react'34function RouteComponent() {5 const { deferredData } = Route.useLoaderData()67 return (8 <div>9 <h1>页面标题(立即显示)</h1>10 11 <Suspense fallback={<p>正在努力加载慢速数据...</p>}>12 <Await promise={deferredData}>13 {(data) => (14 <div>15 {/* 这里是数据加载成功后的渲染逻辑 */}16 <p>数据内容: {data.content}</p>17 </div>18 )}19 </Await>20 </Suspense>21 22 </div>23 )24}3. <Await> 的核心属性
| 属性 | 类型 | 说明 |
|---|---|---|
promise | Promise<T> | 必须传入一个正在进行的异步任务。 |
children | (data: T) => ReactNode | 一个函数(Render Child),其参数就是 Promise 解析后的结果。 |
4. 进阶:错误处理
如果 promise 失败了,<Await> 默认会抛出错误并触发最近的 ErrorBoundary。你可以配合 Route 的 errorComponent 使用,或者在局部使用自定义错误边界。
老师案例
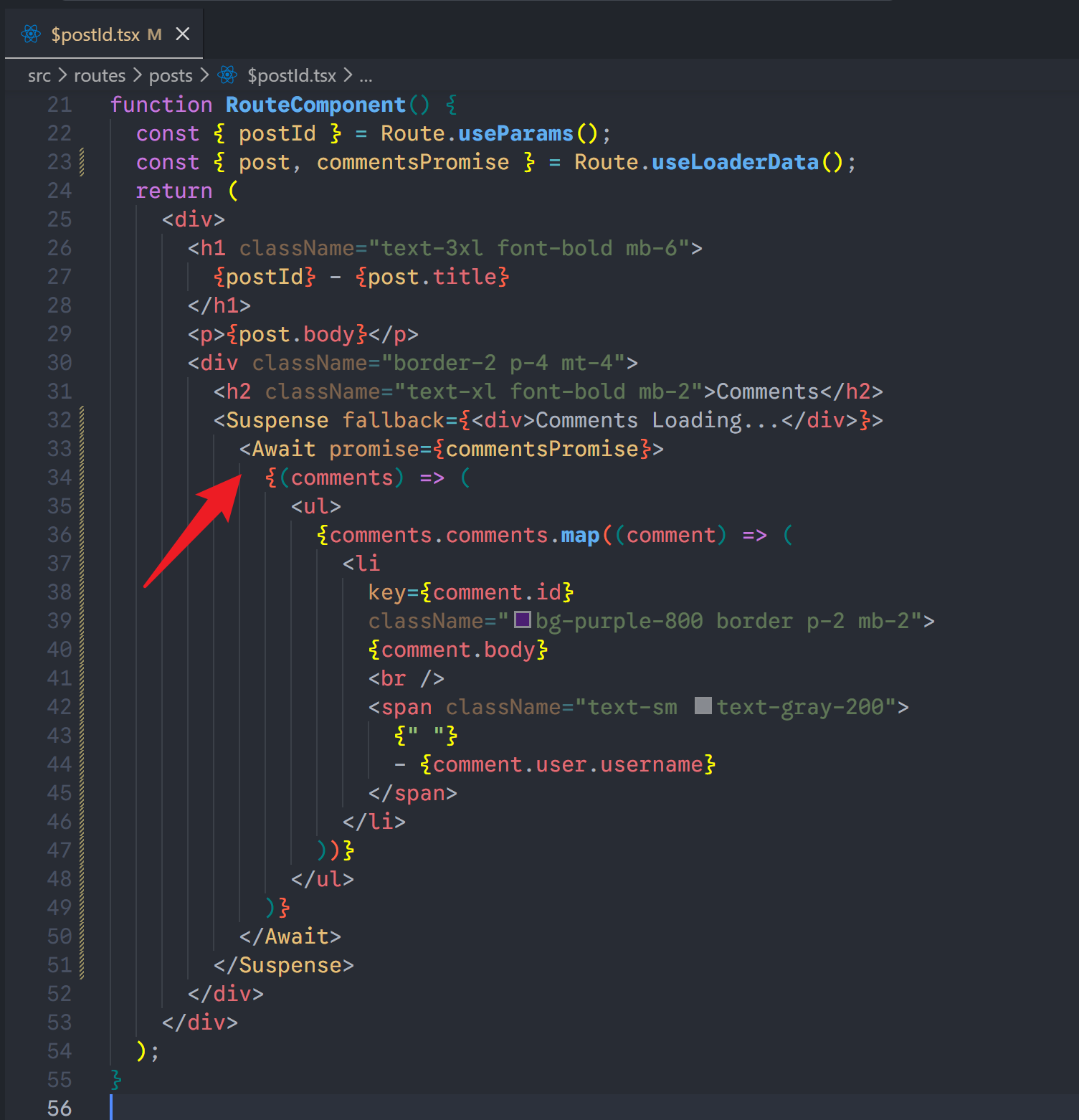
可以看到,post详情页面先显示了,comments里面显示loading效果,等到comments接口返回了,就显示。效果和我预想的一致,很好。